def complexity_embedding(signal, dimension, delay):
N = len(signal) # вимірюємо довжину сигналу
Y = np.zeros((dimension, N - (dimension - 1) * delay)) # ініціалізуємо масив нулів,
# що будуть представляти траєкторії
for i in range(dimension):
Y[i] = signal[i * delay : i * delay + Y.shape[1]] # заповнюємо кожну траєкторію
embedded = Y.T
return embedded # повертаємо результат2 Лабораторна робота № 2
Тема. Використання рекурентного аналізу для моделювання і прогнозування нелінійних динамічних властивостей складних систем
Мета. Навчитися інструментарію нелінійної динаміки, який відноситься до рекурентних властивостей нестаціонарних динамічних рядів
2.1 Теоретичні відомості
Дослідження складних систем, як природних, так і штучних, показали, що в їх основі лежать нелінійні процеси, ретельне вивчення яких необхідне для розуміння і моделювання складних систем. У останні десятиліття набір традиційних (лінійних) методик дослідження був істотно розширений нелінійними методами, одержаними з теорії нелінійної динаміки і хаосу; багато досліджень були присвячені оцінці нелінійних характеристик і властивостей процесів, що протікають в природі (скейлінг, фрактальна розмірність). Проте більшість методів нелінійного аналізу вимагає або достатньо довгих, або стаціонарних рядів даних, які досить важко одержати в природний спосіб. Більш того, було показано, що дані методи дають задовільні результати для моделей реальних систем, що ідеалізуються. Ці чинники вимагали розробки нових методик нелінійного аналізу даних.
Стан природних або штучних систем, як правило, змінюється в часі. Вивчення цих, часто складних процесів — важлива задача в багатьох дисциплінах, дозволяє зрозуміти і описати їх суть, наприклад, для прогнозування стану на деякий час у майбутнє. Метою таких досліджень є знаходження математичних моделей, які б достатньо відповідали реальним процесам і могли б бути використані для розв’язання поставлених задач.
Розглянемо ідею і коротко опишемо теорію рекурентного аналізу, наведемо деякі приклади, розглянемо його можливі області застосування при аналізі і прогнозування складних фінансово-економічних систем.
2.1.1 Фазовий простір та його реконструкція
Стан системи описується її змінними стану
\[ x^1(t),x^2(t),...,x^d(t), \]
де верхній індекс — номер змінної. Набір із \(d\) змінних стану в момент часу \(t\) складає вектор стану \(\vec x(t)\) в \(d\)-вимірному фазовому просторі. Даний вектор переміщується в часі та в напрямі, що визначається його вектором швидкості:
\[ \dot{\vec x}(t)=\partial_t\vec x(t)=\vec F(t). \]
Послідовність векторів \(\vec x(t)\) утворює траєкторію у фазовому просторі, причому поле швидкості \(\vec F\) дотичне до цієї траєкторії. Еволюція траєкторії описує динаміку системи і її атрактор. Знаючи \(\vec F\), можна одержати інформацію про стан системи в момент \(t\) шляхом інтегрування виразу. Оскільки форма траєкторії дозволяє судити про характер процесу (періодичні або хаотичні процеси мають характерні фазові портрети), то для визначення стану системи не обов’язково проводити інтегрування, достатньо побудувати графічне відображення траєкторії.
При дослідженні складних систем часто відсутня інформація щодо всіх змінних стану, або не всі з них можливо виміряти. Як правило, маємо єдине спостереження, проведене через дискретний часовий інтервал \(\Delta t\). Таким чином, вимірювання записуються у вигляді ряду \(u_i(t)\) i, де \(t=i\cdot \Delta t\). Інтервал \(\Delta t\) може бути постійним, проте це не завжди можливо і створює проблеми для застосування стандартних методів аналізу даних, що вимагають рівномірної шкали спостережень.
Взаємодії і їх кількість у складних системах такі, що навіть за однією змінною стану можна судити про динаміку всієї системи в цілому (даний факт був встановлений групою американських учених при вивченні турбулентності). Таким чином, еквівалентна фазова траєкторія, що зберігає структури оригінальної фазової траєкторії, може бути відновлена з одного спостереження або часового ряду [1] за теоремою Такенса (Takens) методом часових затримок [2]:
\[ \widehat{\vec x}(t)=(u_i,u_{i+\tau},...,u_{i+(m-1)\tau}). \]
Тут \(m\) — розмірність вкладення, \(\tau\) — часова затримка (реальна часова затримка визначається як \(\tau \cdot \Delta t\)). Топологічні структури відновленої траєкторії зберігаються, якщо \(m \geq 2 \cdot d+1\), де \(d\) — розмірність атрактора [2]. На практиці у більшості випадків атрактор може бути відновлений і при \(m \leq 2d\). Затримка, як правило, вибирається апріорно.
Існує кілька підходів до вибору мінімально достатньої розмірності \(m\), крім аналітичного. Високу ефективність показали методи, засновані на концепції фальшивих найближчих точок (false nearest neighbours, FNN). Суть її заключається у тому, що при зменшенні розмірності вкладення відбувається збільшення кількості фальшивих точок, що потрапляють в околицю будь-якої точки фазового простору. Звідси витікає простий метод — визначення кількості FNN як функції розмірності. Існують і інші методи, засновані на цій концепції, наприклад, визначення відносин відстаней між одними і тими ж сусідніми точками при різних \(m\). Розмірність атрактора також може бути визначена за допомогою крос-кореляційних сум.
2.1.2 Рекурентний аналіз
Процесам у природі властива яскраво виражена рекурентна поведінка, така, як періодичність або іррегулярна циклічність. Більш того, рекурентність (повторюваність) станів у значенні проходження подальшої траєкторії достатньо близько до попередньої є фундаментальною властивістю дисипативних динамічних систем. Ця властивість була відмічена ще в 80-х роках XIX століття французьким математиком Пуанкаре (Poincare) і згодом сформульовано у вигляді “теореми рекурентності”, опублікованої в 1890 р.:
Примітка
Якщо система зводить свою динаміку до обмеженої підмножини фазового простору, то вона майже напевно, тобто з вірогідністю, практично рівною 1, скільки завгодно близько повертається до якого-небудь спочатку заданого режиму
Суть цієї фундаментальної властивості у тому, що, навіть мале збурення в складній динамічній системі може привести систему до експоненціального відхилення від її стану, через деякий час система прагне повернутися до стану близького до попереднього, і проходить при цьому подібні етапи еволюції.
Переконатися в цьому можна за допомогою графічного зображення траєкторії системи у фазовому просторі. Проте можливості такого аналізу сильно обмежені. Як правило, розмірність фазового простору складної динамічної системи більша трьох, що робить практично незручним його розгляд напряму; єдина можливість — проекції в дво- і тривимірні простори, що часто не дає вірного уявлення про фазовий портрет.
У 1987 р. Екман (Eckmann) і співавтори запропонували спосіб відображення \(m\)-вимірної фазової траєкторії станів системи \(\vec x(t)\) завдовжки \(N\) на двовимірну квадратну двійкову матрицю розміром \(N \times N\) [3], в якій 1 (чорна точка) відповідає повторенню стану при деякому часі \(i\) в деякий інший час \(j\), а обидві координатні осі є осями часу. Таке представлення було назване рекурентною картою або діаграмою (recurrence plot, RP), оскільки воно фіксує інформацію про рекурентну поведінку системи.
Математично вищесказане описується як
\[ R_{i,j}^{m,\varepsilon_i}=\Theta(\varepsilon_i-\| \vec x_i - \vec x_j \|), \quad \vec x \in \Re^m, \quad i, j=1,...,N, \]
де \(N\) — кількість даних станів, \(x_i, \varepsilon_i\) — розмір околиці точки \(\vec x\) у момент \(i\), \(\| \cdot \|\) — норма і \(\Theta(\cdot)\) — функція Хевісайда.
Непрактично і, як правило, неможливо знайти повну рекурентність у значенні \(\vec x_i \equiv \vec x_j\) (стан динамічної, а особливо — хаотичної системи не повторюється повністю еквівалентно початковому стану, а підходить до нього скільки завгодно близько). Таким чином, рекурентність визначається як достатня близькість стану \(\vec x_j\) до стану \(\vec x_i\). Іншими словами, рекурентними є стани \(\vec x_j\), які потрапляють в \(m\)-вимірну околицю з радіусом \(\varepsilon_i\) і центром в \(\vec x_i\). Ці точки \(\vec x_j\) називаються рекурентними точками (recurrence points) [4,5].
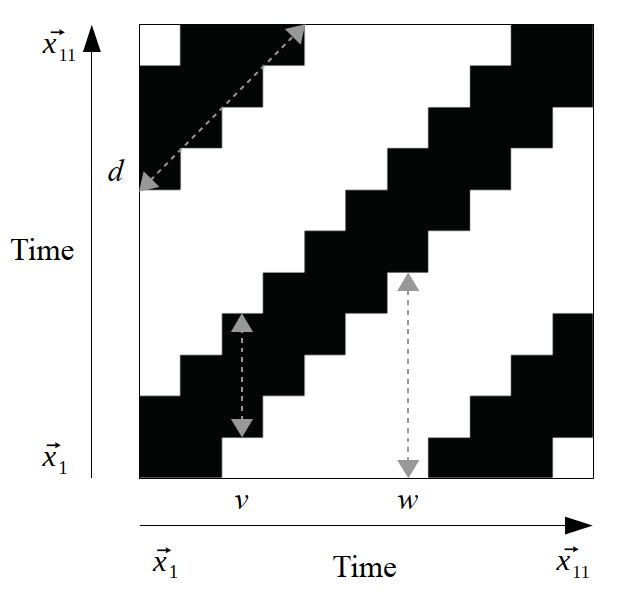
Оскільки \(R_{i,i}=1\), \(i=1,...,N\) за визначенням, то рекурентна діаграма завжди містить чорну діагональну лінію — лінію ідентичності (line of identity, LOI) під кутом \(\pi/4\) до осей координат. Довільно узята рекурентна точка не несе якої-небудь корисної інформації про стани в часи \(i\) і \(j\). Тільки вся сукупність рекурентних точок дозволяє відновити властивості системи.
Зовнішній вигляд рекурентної діаграми дозволяє судити про характер процесів, які протікають в системі, наявності і впливі шуму, станів повторення і завмирання (ламінарності), здійсненні в ході еволюції системи різких змін стану (екстремальних подій).
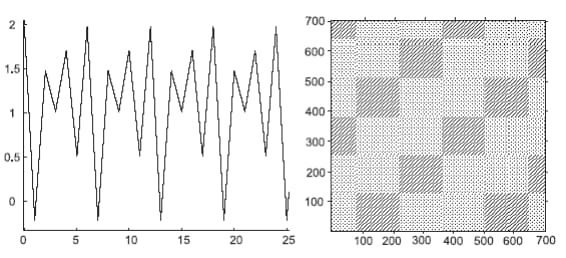
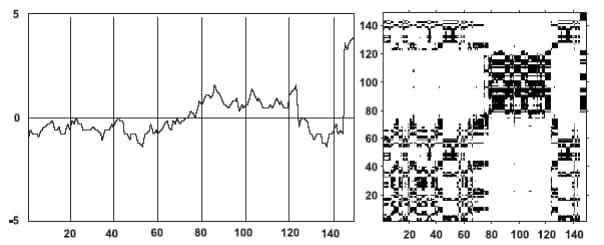
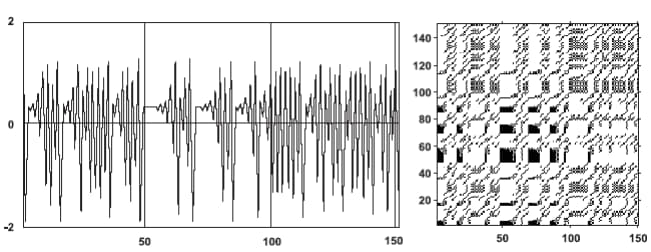
2.1.3 Аналіз діаграм
Очевидно, що процеси різної поведінки даватимуть рекурентні діаграми з різним рисунком. Таким чином, візуальна оцінка діаграм може дати уявлення про еволюцію досліджуваної траєкторії. Виділяють два основних класи структури зображення: топологія (typology), що представляється крупномасштабними структурами, і текстура (texture), що формується дрібномасштабними структурами.
Топологія дає загальне уявлення про характер процесу. Виділяють чотири основні класи:
- однорідні рекурентні діаграми типові для стаціонарних і автономних систем, в яких час релаксації малий у порівнянні з довжиною ряду;
- періодичні структури, що повторюються (діагональні лінії, патерни у шаховому порядку) відповідають різним осцилюючим системам з періодичністю в динаміці;
- дрейф відповідає системам з параметрами, що поволі змінюються, і це робить білими лівий верхній і правий нижній кути рекурентної діаграми;
- різкі зміни в динаміці системи, рівно як і екстремальні ситуації, обумовлюють появу білих областей або смуг.
Рекурентні діаграми спрощують виявлення екстремальних і рідкісних подій.




Детальний розгляд рекурентних діаграм дозволяє виявити дрібномасштабні структури — текстуру, яка складається з простих точок, діагональних, горизонтальних і вертикальних ліній. Комбінації вертикальних і горизонтальних ліній формують прямокутні кластери точок:
- самотні, окремо розташовані рекурентні точки з’являються в тому разі, коли відповідні стани рідкісні, або нестійкі в часі, або викликані сильною флуктуацією. При цьому вони не є ознаками випадковості або шуму;
- діагональні лінії \(R_{i+k, j+k}=1\) (при \(k = 1...l\) де \(l\) — довжина діагональної лінії) з’являються у разі, коли сегмент траєкторії у фазовому просторі пролягає паралельно іншому сегменту, тобто траєкторія повторює саму себе, повертаючись в одну і ту ж область фазового простору у різний час. Довжина таких ліній визначається часом, протягом якого сегменти траєкторії залишаються паралельними; напрям (кут нахилу) ліній характеризує внутрішній час підпроцесів, відповідних даним сегментам траєкторії. Проходження ліній паралельно лінії ідентичності (під кутом \(\pi/4\) до осей координат) свідчить про однаковий напрям сегментів траєкторії, перпендикулярно — про протилежний (“відображені” сегменти), що може також бути ознакою реконструкції фазового простору з невідповідною розмірністю вкладення. Нерегулярна поява діагональних ліній є ознакою хаотичного процесу;
- вертикальні (горизонтальні) лінії \(R_{i, j+k}=1\) (при \(k = 1...\upsilon\), де \(\upsilon\) — довжина вертикальної або горизонтальної лінії) виділяють проміжки часу, в котрі стан системи не змінюється або змінюється не суттєво (система як би “заморожена” на цей час), що є ознакою “ламінарних” станів.
2.2 Хід роботи
Спочатку побудуємо дво- та тривимірні фазові портрети як для модельних значень, так і для реальних. Використовуватимемо бібліотеки neurokit2 для побудови атракторів та рекурентного аналізу.
2.2.1 Процедура реконструкції фазового простору
Для побудови фазового портрету скористаємось методами complexity_attractor() та complexity_embedding() бібліотеки neuralkit2. Синтаксис complexity_attractor() виглядає наступним чином:
complexity_attractor(embedded='lorenz', alpha='time', color='last_dim', shadows=True, linewidth=1, **kwargs)
Параметри:
- embedded (Union[str, np.ndarray]) — результат функції
complexity_embedding(). Також може бути рядком, наприклад,"lorenz"(атрактор Лоренца) або"rossler"(атрактор Рьосслера); - alpha (Union[str, float]) — прозорість ліній;
- color (str) — колір графіку. Якщо
"last_dim", буде використано останній вимір (максимум 4-й) вбудованих даних, коли розмірність більша за 2. Корисно для візуалізації глибини (для 3-вимірного вбудовування), або четвертого виміру, але працюватиме це повільно; - shadows (bool) — якщо значення
True, 2D-проекції буде додано до бокових сторін 3D-атрактора; - linewidth (float) — задає товщину лінії;
- kwargs — до палітри кольорів (наприклад,
name="plasma") або до симулятора системи Лоренца передаються додаткові аргументи ключових слів, такі якduration(за замовчуванням = 100),sampling_rate(за замовчуванням = 10),sigma(за замовчуванням = 10),beta(за замовчуванням = 8/3),rho(за замовчуванням = 28).
Як вже зазначалося, побудова фазового простору, на основі якого і проводитиметься рекурентний аналіз, вимагає реконструкції. Виконати реконструкції фазового простору із одновимірного часового ряду можна із використанням методу часових затримок.
Метод часових затримок є однією з ключових концепцій науки про складність. Він базується на ідеї, що динамічна система може бути описана вектором чисел, який називається її “станом”, і має на меті забезпечити повний опис системи в даний момент часу. Множина всіх можливих станів називається “простором станів”.
Теорема Такенса [2] припускає, що послідовність вимірювань динамічної системи містить у собі всю інформацію, необхідну для повної реконструкції простору станів. Метод часових затримок намагається визначити стан \(s\) системи в певний момент часу \(t\), шукаючи в минулій історії спостережень схожі стани, і, вивчаючи еволюцію схожих станів, виводити інформацію про майбутнє системи.
Як візуалізувати динаміку системи? Послідовність значень стану в часі називається траєкторією. Залежно від системи, різні траєкторії можуть еволюціонувати до спільної підмножини простору станів, яка називається атрактором. Наявність та поведінка атракторів дає інтуїтивне уявлення про досліджувану динамічну систему.
Одже, згідно Такенсу, ідея полягає в тому, щоб на основі одиничних вимірювань системи, отримати \(m\)-розмірні реконструйовані часові вкладення
\[ \vec{x}_i = \left( x_i, x_{i+\tau}, ... , x_{i+(m-1)\tau} \right), \tag{2.1}\]
а \(i\) проходить в діапазоні \(1,..., N-(m-1)\tau\); значення \(\tau\) представляє часову затримку, а \(m\) — це розмірність вкладень (кількість змінних, що включає кожна траєкторія).
Код для реконструкції фазового простору може виглядати наступним чином:
Для реконструкції фазового простору використовуватимемо метод complexity_embedding(). Його синтаксис:
complexity_embedding(signal, delay=1, dimension=3, show=False, **kwargs)
Параметри:
- signal (Union[list, np.array, pd.Series]) — сигнал (тобто часовий ряд) у вигляді вектора значень. Також може бути рядком, наприклад,
"lorenz"(атрактор Лоренца),"rossler"(атрактор Росслера) або"clifford"(атрактор Кліффорда) для отримання попередньо визначеного атрактора; - delay (int) — часова затримка (часто позначається \(\tau\) іноді називають запізненням). Ще розглянемо метод
complexity_delay()для оцінки оптимального значення цього параметра; - dimension (int) — розмірність вкладень (\(m\), іноді позначається як \(d\)). Далі звернемось до методу
complexity_dimension(), щоб оцінити оптимальне значення для цього параметра; - show (bool) — побудувати графік реконструйованого атрактора;
- kwargs — інші аргументи, що передаються до
complexity_attractor().
Повертає:
- array — реконструйований атрактор розміру
length - (dimension - 1) * delay.
Далі імпортуємо необхідні для подальшої роботи модулі:
import matplotlib.pyplot as plt
import numpy as np
import neurokit2 as nk
import yfinance as yf
import scienceplots
import pandas as pdІ виконаємо налаштування рисунків для виводу:
plt.style.use(['science', 'notebook', 'grid']) # стиль, що використовуватиметься
# для виведення рисунків
size = 16
params = {
'figure.figsize': (8, 6), # встановлюємо ширину та висоту рисунків за замовчуванням
'font.size': size, # розмір фонтів рисунку
'lines.linewidth': 2, # товщина ліній
'axes.titlesize': 'small', # розмір титулки над рисунком
'axes.labelsize': size, # розмір підписів по осям
'legend.fontsize': size, # розмір легенди
'xtick.labelsize': size, # розмір розмітки по осі Ох
'ytick.labelsize': size, # розмір розмітки по осі Ох
"font.family": "Serif", # сімейство стилів підписів
"font.serif": ["Times New Roman"], # стиль підпису
'savefig.dpi': 300, # якість збережених зображень
'axes.grid': False # побудова сітки на самому рисунку
}
plt.rcParams.update(params) # оновлення стилю згідно налаштуваньТепер розглянемо можливість використання методу часових затримок і отриманих у подальшому атракторів у якості індикатора складності. Як і в попередній роботі, для прикладу завантажимо часовий ряд Біткоїна за період з 1 вересня 2015 по 1 березня 2020, використовуючи yfinance:
symbol = 'BTC-USD' # Символ індексу
start = "2015-09-01" # Дата початку зчитування даних
end = "2020-03-01" # Дата закінчення зчитування даних
data = yf.download(symbol, start, end) # вивантажуємо дані
time_ser = data['Close'].copy() # зберігаємо саме ціни закриття
xlabel = 'time, days' # підпис по вісі Ох
ylabel = symbol # підпис по вісі ОуYF.download() has changed argument auto_adjust default to True[*********************100%***********************] 1 of 1 completed
Увага
Виконайте цей блок, якщо хочете зчитати дані не з Yahoo! Finance, а із власного файлу. Зрозуміло, що й аналіз результатів, і висновки залежать від того з яким рядом ми працюємо
symbol = 'sMpa11' # Символ індексу
path = "databases\sMpa11.txt" # шлях по якому здійснюється зчитування файлу
data = pd.read_csv(path, # зчитування даних
names=[symbol])
time_ser = data[symbol].copy() # копіюємо значення кривої
# "напруга-видовження" до окремої змінної
xlabel = r'$\varepsilon$' # підпис по вісі Ох
ylabel = symbol # підпис по вісі ОуВиводимо досліджуваний ряд:
fig, ax = plt.subplots() # Створюємо порожній графік
ax.plot(time_ser.index, time_ser.values) # Додаємо дані до графіку
ax.legend([symbol]) # Додаємо легенду
ax.set_xlabel(xlabel) # Встановимо підпис по вісі Ох
ax.set_ylabel(ylabel) # Встановимо підпис по вісі Oy
plt.xticks(rotation=45) # оберт позначок по осі Ох на 45 градусів
plt.savefig(f'{symbol}.jpg') # Зберігаємо графік
plt.show(); # Виводимо графік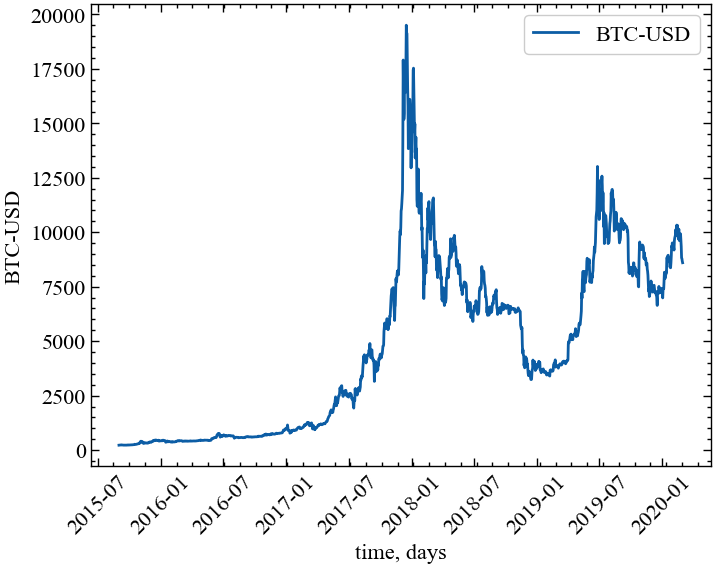
Спочатку оберемо вид ряду: 1 - вихідний ряд; 2 - детермінований (різниця між теперішнім та попереднім значенням); 3 - прибутковості звичайні; 4 - стандартизовані прибутковості; 5 - абсолютні значення (волатильності); 6 - стандартизований ряд.
Для подальших розрахунків накращим варіантом буде вибір стандартизованого вихідного ряду або прибутковостей, оскільки значення вихідного часового ряду відрізняються на декілька порядків, і можуть сильно перевищувати встановлений параметр \(\varepsilon\). У цьому випадку для вихідних значень, що сильно різняться між собою, увесь часовий діапазон буде розглядатися як нерекурентний.
Спочатку визначимо функції для виконання перетворення ряду:
def transformation(signal, ret_type):
for_rec = signal.copy()
if ret_type == 1: # Зважаючи на вид ряду, виконуємо
# необхідні перетворення
pass
elif ret_type == 2:
for_rec = for_rec.diff()
elif ret_type == 3:
for_rec = for_rec.pct_change()
elif ret_type == 4:
for_rec = for_rec.pct_change()
for_rec -= for_rec.mean()
for_rec /= for_rec.std()
elif ret_type == 5:
for_rec = for_rec.pct_change()
for_rec -= for_rec.mean()
for_rec /= for_rec.std()
for_rec = for_rec.abs()
elif ret_type == 6:
for_rec -= for_rec.mean()
for_rec /= for_rec.std()
for_rec = for_rec.dropna().values
return for_recі тепер виконаємо перетворення, використовуючи дану функцію:
signal = time_ser.copy()
ret_type = 6 # вид ряду: 1 - вихідний,
# 2 - детрендований (різниця між теп. значенням та попереднім)
# 3 - прибутковості звичайні,
# 4 - стандартизовані прибутковості,
# 5 - абсолютні значення (волатильності)
# 6 - стандартизований ряд
for_rec = transformation(signal, ret_type).flatten()Оскільки ми не матимемо змоги візуалізувати багатовимірний фазовий простір (\(m>3\)), ми послуговуватимемось значеннями \(m=2\) та \(m=3\). Значення \(\tau\) будемо варіювати як із власних переконань, так і з опорою на функціонал бібліотеки neuralkit2.
Скористаємось методом complexity_simulate() для генерації різних тестових сигналів:
signal_random_walk = nk.complexity_simulate(duration=30,
sampling_rate=100,
method="randomwalk") # симуляція випадкового блуканняnk.complexity_attractor(embedded=nk.complexity_embedding(signal_random_walk, dimension=2, delay=100),
alpha=1,
color="orange");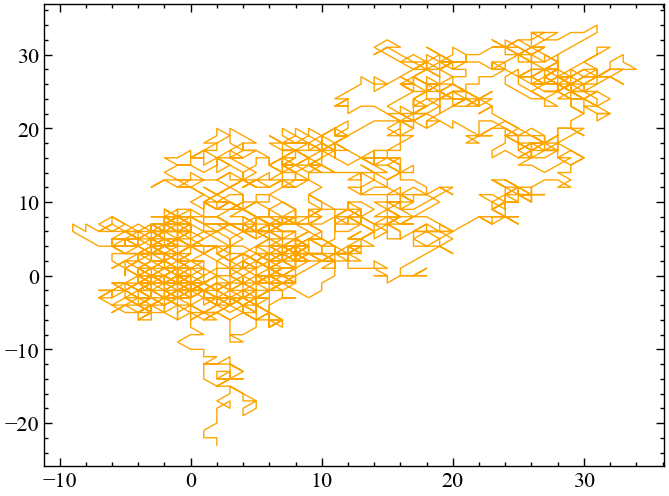
nk.complexity_attractor(nk.complexity_embedding(signal_random_walk, dimension=3, delay=100),
alpha=1,
color="orange");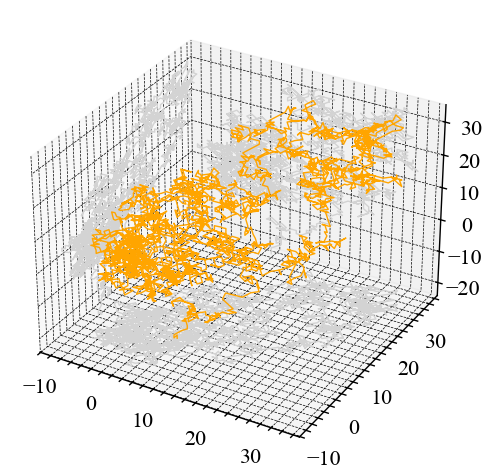
signal_ornstein = nk.complexity_simulate(duration=30,
sampling_rate=100,
method="ornstein") # симуляція системи Орнштайнаnk.complexity_attractor(nk.complexity_embedding(signal_ornstein, dimension=2, delay=100),
alpha=1,
color="red");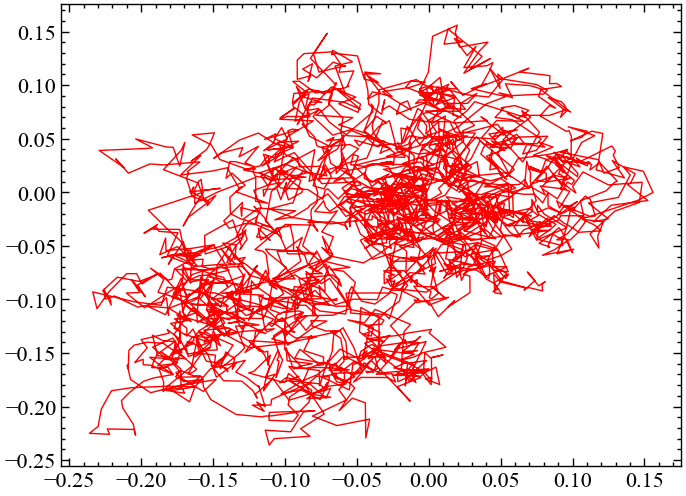
nk.complexity_attractor(nk.complexity_embedding(signal_ornstein, dimension=3, delay=100),
alpha=1,
color="red");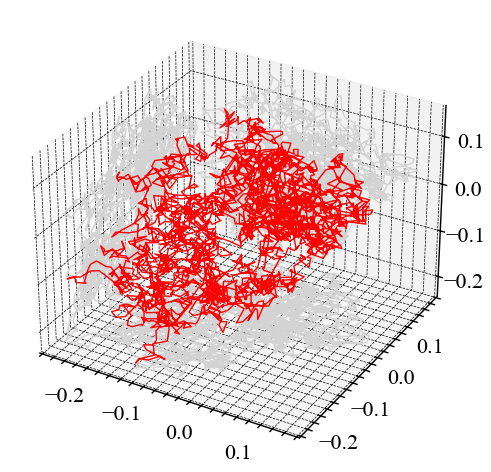
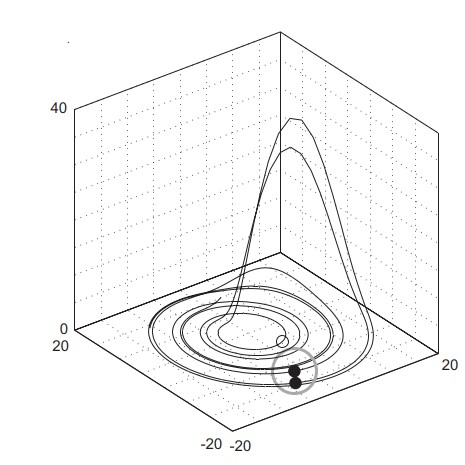
nk.complexity_attractor(color = "last_dim", alpha="time", duration=1);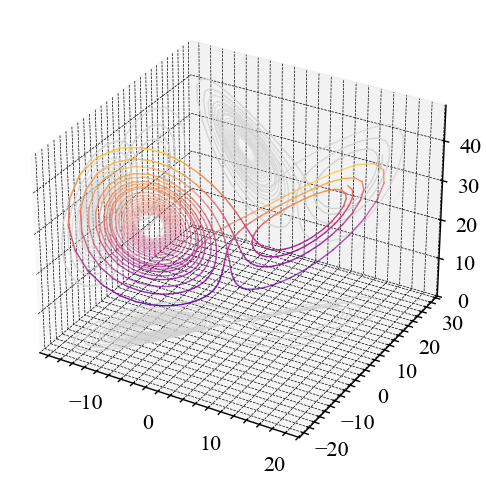
nk.complexity_attractor("rossler", color = "blue", alpha=1, sampling_rate=5000);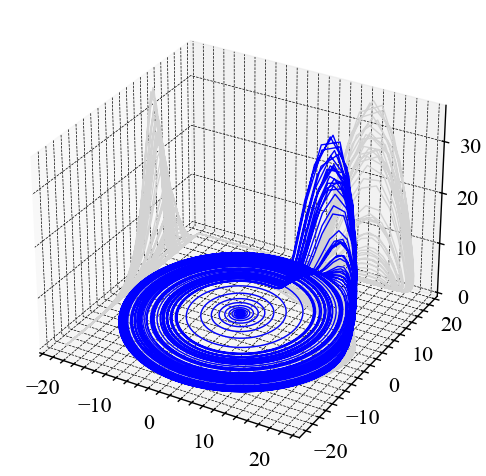
nk.complexity_attractor(nk.complexity_embedding(for_rec, dimension=2, delay=100),
alpha=1,
color="maroon");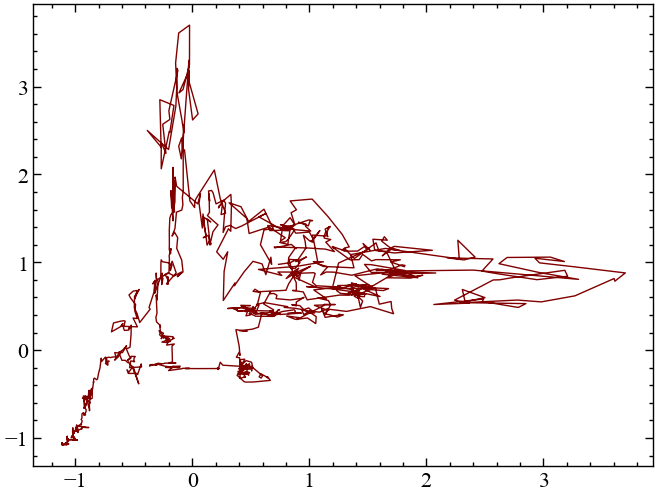
nk.complexity_attractor(nk.complexity_embedding(for_rec, dimension=3, delay=100),
alpha=1,
color="maroon");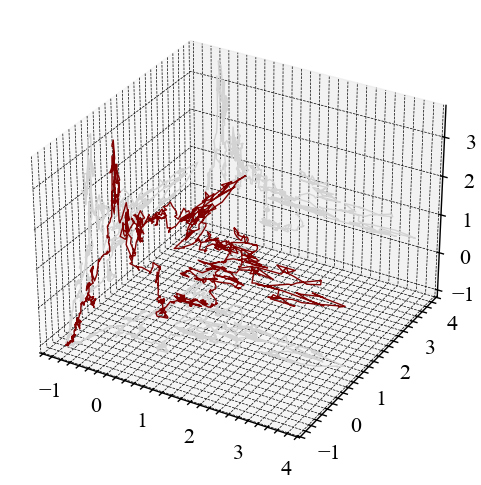
Автоматизований підбір параметрів
У зазначених вище прикладах ми обирали параметри \(m\) і \(\tau\) згідно нашими власними міркуваннями. Але на практиці бажано було б, щоб зазначені параметри обирались автоматично, спираючись на конкретну статистичну процедуру. Бібліотека neurokit2 представляє функціонал для автоматичного підбору параметрів розмірності та часової затримки. У завданнях самостійної роботи буде надано короткий опис алгоритмів для автоматичного підбору розмірності атрактору та часової затримки. В основній частині лабораторної роботи для побудови рекурентних діаграм будуть використанні самостійно підібрані значення \(m\) і \(\tau\)
2.2.2 Побудова рекурентної матриці
Як вже зазначалося, рекурентний аналіз на основі реконструйованих траєкторій фазового простору визначає кількість і тривалість рекурентних станів динамічної системи.
Ми маємо змогу побудувати рекурентну матрицю, використовуючи метод recurrence_matrix().
Його синтаксис виглядає наступним чином:
recurrence_matrix(signal, delay=1, dimension=3, tolerance='default', show=False)
Параметри:
- signal (Union[list, np.ndarray, pd.Series]) — сигнал у вигляді вектора значень;
- delay (int) — затримка в часі;
- dimension (int) — розмірність вкладень, \(m\);
- tolerance (float) — радіус \(\varepsilon\) багатовимірного околу, в межах якого шукаються рекурентні траєкторії, а дві точки даних вважаються схожими. Якщо
"sd"(за замовчуванням), буде встановлено значення \(0.2 \cdot SD_{signal}\). Емпіричним правилом є встановлення \(\varepsilon\) таким чином, щоб відсоток точок, класифікованих як рекурентні, становив приблизно 2-5%; - show (bool) — візуалізувати рекурентну матрицю.
Повертає:
- np.ndarray — рекурентну матрицю;
- np.ndarray — матрицю відстаней.
Побудуємо рекурентну матрицю для фрагменту вихідних значень Біткоїна, його прибутковостей та стандартизованого фоагменту його вихідного ряду. Розмірність \(m=4\), часова затримка \(\tau=1\). Спробуємо різні варіанти \(\varepsilon\):
- для вихідного ряду \(\varepsilon=100\);
- для прибутковостей та стандартизованого ряду \(\varepsilon=0.8\).
Примітка для побудови матриці рекурентності
Як уже зазначалось на початку, рекурентна діаграма — це двовимірна квадратна двійкова матриця розміром \(N^2\). Одним із її основних недоліків є те, що вона погано масштабується на великих даних. Наприклад, якщо ви плануєте досліджувати часовий ряд довжиною 1000000 значень, тоді рекурентна матриця буде складатись із 1000000000000 білих і чорних точок, що може бути викликом для вашого процесора та оперативної пам’яті. Тому в подальшому ми пропонуємо будувати рекурентну матрицю не для всього ряду, а тільки для його підмножини. Для цього ми визначимо змінні початкового (idx_beg) та кінцевого (inx_end) відліку в межах якого буде здійснюватись побудова рекурентної матриці
idx_beg = 1000 # кінцевий відлік
idx_end = 1500 # початковий відлік
fragm = signal[idx_beg:idx_end]
# виконуємо приведення вихідного сигналу до прибутковостей
ret_type = 4
ret = transformation(fragm, ret_type).flatten()
# приводимо вихідний ряд до стандартизованого виду
ret_type = 6
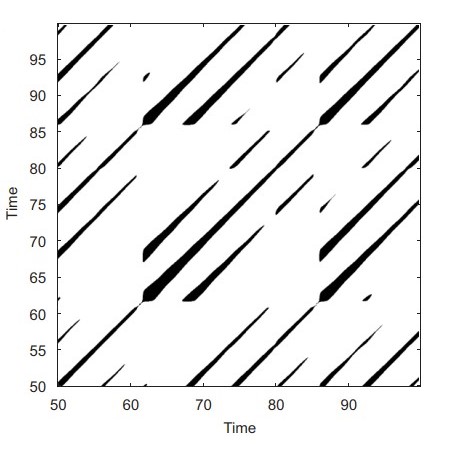
for_rec = transformation(fragm, ret_type).flatten()rc, _ = nk.recurrence_matrix(fragm.values.flatten(),
delay=1,
dimension=4,
tolerance=100,
show=True)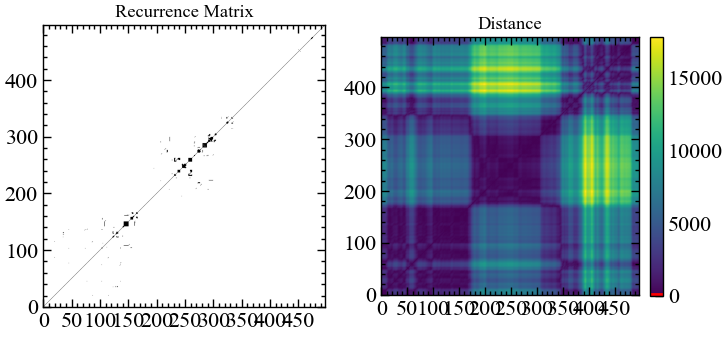
Як можна бачити з рисунку 2.14 всі траєкторії для простору вихідних значень за абсолютною шкалою залишаються доволі віддаленими один від одного. Для розпізнавання рекурентних закономірностей нам потребується поступово нарощувати \(\varepsilon\). З цього рисунку видно, що \(\varepsilon=100\) буде замало.
Тепер спробуємо трохи нормалізувати значення вихідного фрагменту Біткоїна, аби реконструйовані траєкторії не знаходились занадто віддаленими один від одного. Для цього розрахуємо стандартизовані прибутковості:
# будуємо рекурентну матрицю
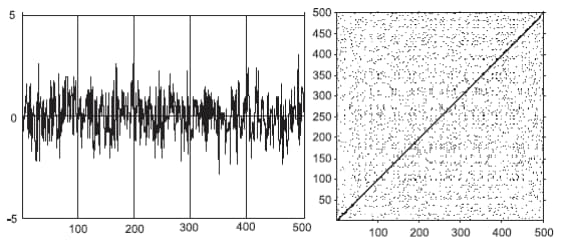
rc, _ = nk.recurrence_matrix(ret,
delay=1,
dimension=4,
tolerance=0.8,
show=True)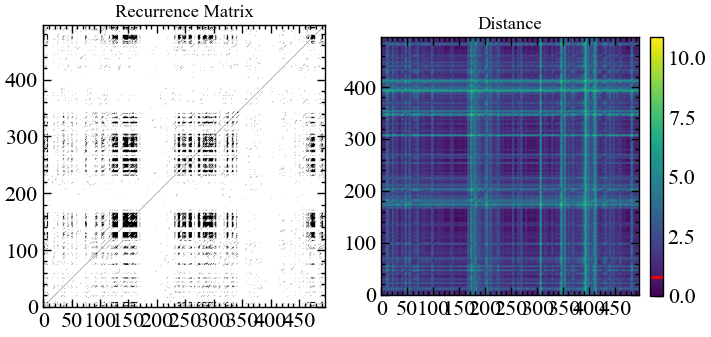
Тепер можемо бачити, що Біткоїн став характризуватися чорними смугами, що відображають динаміку певних детермінованих процесів. У той же час білі смуги характеризують періоди абсолютно аномальної (непередбачуваної) поведінки на даному ринку. Видно, що прибутковості залишаються доволі некорельованими, про що і свідчить переважне домінування саме білих областей.
Спробуємо тепер подивитись на стандартизований вихідний ряд:
# будуємо рекурентну матрицю
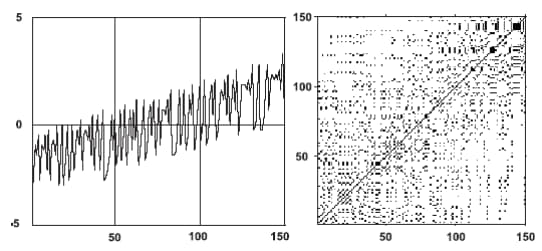
rc, _ = nk.recurrence_matrix(for_rec,
delay=1,
dimension=4,
tolerance=0.8,
show=True)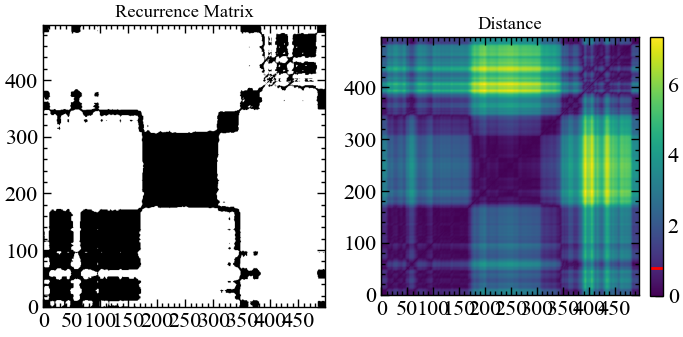
На початку свого існування Біткоїн характеризувався доволі високим ступенем передбачуваності, низькою волатильністю коливань. Надалі почали домінувати білі області, а зараз Біткоїну властива динаміка схожа з броунівським рухом.
2.3 Висновок
У даній лабораторній роботі було продемонстровано можливість дослідження складних нелінійних систем із використанням рекурентних діаграм. На прикладі Біткоїна було показано, що складним фінансовим систем властива топологія узагальненого броунівського руху, де рекурентність може варіюватись із плином часу. Тобто, той самий криптовалютний ринок характеризується мінливістю ступеня передбачуваності. Змога знаходження станів передбачуваності з точки зору рекурентних діаграм надає перспективи для їх використання разом із методами прогнозування та побудови індикаторів-передвісників.
2.4 Завдання для самостійної роботи
- Отримати індекс часового ряду у викладача
- Провести дослідження його рекурентних властивостей згідно інструкції
- Порівняти фазові портрети і рекурентні діаграми для стандартизованого вихідного ряду та прибутковостей. Що спільного між ними і чим вони відрізняються?
- Провести побудову фазових портретів і рекурентних діаграм для вашого часового ряду із використанням процедур автоматичного підбору параметрів розмірності вкладень і часової затримки. Порівняти результати з тими, що були отримані без використання даних методів і зробити висновки
Для виконання 4-го завдання самостійної роботи
Далі надається опис алгоритмів для автоматизованого підбору розмірності реконструйованого фазового простору та часової затримки
2.4.1 Автоматизований підбір параметра часової затримки, \(\tau\)
Часова затримка \(\tau\) (також відома як L) є одним з двох критичних параметрів, що беруть участь у процедурі реконструкції фазового простору. Значення \(L\) відповідає затримці у відліках між вихідним сигналом і його затриманою версією (версіями). Іншими словами, скільки відліків ми розглядаємо між певним станом сигналу та його найближчим минулим станом.
Якщо \(\tau\) менше оптимального теоретичного значення, послідовні координати стану системи корельовані і атрактор недостатньо розгорнутий. І навпаки, коли \(\tau\) більше, ніж повинно бути, послідовні координати майже незалежні, що призводить до некорельованої та неструктурованої хмари точок.
Вибір параметрів затримки та розмірності представляє нетривіальну задачу. Один з підходів полягає у їх (напів)незалежному виборі (оскільки вибір розмірності часто вимагає затримки) за допомогою функцій complexity_delay() та complexity_dimension(). Однак, існують методи спільного оцінювання, які намагаються знайти оптимальну затримку та розмірність одночасно.
Зауважте також, що деякі автори (наприклад, Розенштейн, 1994) пропонують спочатку визначити оптимальну розмірність вбудовування, а потім розглядати оптимальне значення затримки як оптимальну затримку між першою та останньою координатами затримки (іншими словами, фактична затримка має дорівнювати оптимальній затримці, поділеній на оптимальну розмірність вбудовування мінус 1).
Декілька авторів запропонували різні методи для вибору затримки:
- Фрейзер і Свінні (1986) [8] пропонують використовувати перший локальний мінімум взаємної інформації між затриманим і незатриманим часовими рядами, ефективно визначаючи значення \(\tau\), для якого вони діляться найменшою інформацією (і де атрактор є найменш надлишковим). На відміну від автокореляції, взаємна інформація враховує також нелінійні кореляції;
- Тейлер (1990) [9] запропонував вибирати таке значення \(\tau\), при якому автокореляція між сигналом та його зміщенною версією при \(\tau\) вперше перетинає значення \(1/e\). Методи, що базуються на автокореляції, мають перевагу за часом обчислень, коли вони знаходяться за допомогою алгоритму швидкого перетворення Фур’є (fast Fourier transform, FFT);
- Касдаглі (1991) [10] пропонує замість цього брати перший нульовий перетин автокореляції;
- Розенштейн (1993, 1994) [11,12] вважає, що слід апроксимувати точку, де функція автокореляцій падає до \(\left( 1-1/e \right)\) від свого максимального значення. Або ж наближатися до точки, близької до 40% нахилу середнього зміщення від діагоналі;
- Кім (1999) [13] оцінює \(\tau\) за допомогою кореляційного інтегралу, який називається C-C методом, і який, як виявилося, узгоджується з результатами, отриманими за допомогою методу взаємної інформації. Цей метод використовує статистику в реконструйованому фазовому просторі, а не аналізує часову еволюцію ряду. Однак час обчислень є значно довшим через необхідність порівнювати кожну унікальну пару парних векторів у реконструйованому сигналі на кожну затримку;
- Лайл (2021) [14] описує “Реконструкцію симетричного проекційного атрактора” (Symmetric Projection Attractor Reconstruction, SPAR), де \(1/3\) від домінуючої частоти (тобто довжини середнього “циклу”) може бути підходящим значенням для приблизно періодичних даних, і робить атрактор чутливим до морфологічних змін. Див. також доповідь Астона. Цей метод також є найшвидшим, але може не підходити для аперіодичних сигналів. Аргумент
algorithm(за замовчуванням"fft") передається до аргументуmethodметодуsignal_psd().
Можна також відмітити метод для об’єднаного підбору параметрів затримки та розмірності.
- Гаутама (2003) [15] зазначає, що на практиці часто використовують фіксовану часову затримку і відповідно регулюють розмірність вбудовування. Оскільки це може призвести до великих значень \(m\) (а отже, до вкладених даних великого розміру) і, відповідно, до повільної обробки, використовується метод оптимізації для спільного визначення \(m\) і \(\tau\) на основі показника entropy ratio.
Розглянемо оптимальні значення розмірності та затримки для часового сигналу Біткоїна:
# виконуємо приведення вихідного сигналу до прибутковостей
ret_type = 4
ret = transformation(signal, ret_type).flatten()
# приводимо вихідний ряд до стандартизованого виду
ret_type = 6
for_rec = transformation(signal, ret_type).flatten()delay, parameters = nk.complexity_delay(for_rec,
delay_max=300, show=True,
method="fraser1986")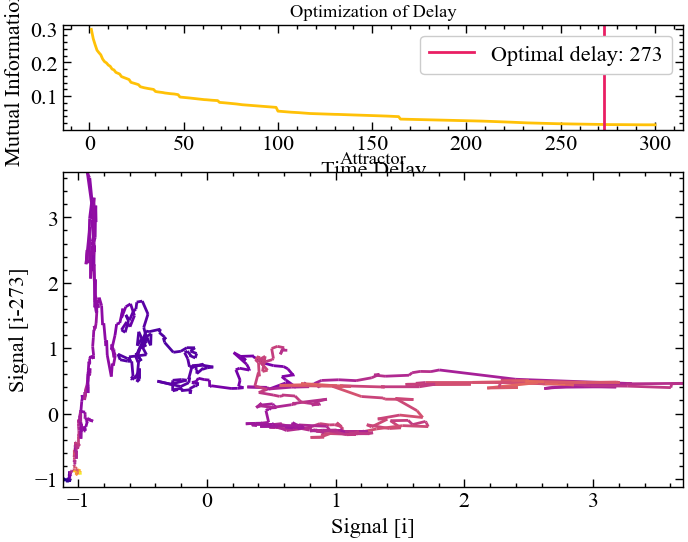
Рис. 2.17 показує, що перший локальний мінімум взаємної інформації для стандартизованих вихідних значень Біткоїна знаходиться на 273 лагу. Для візуального огляду реконструйованого атрактора це значення, можливо, є найбільш адекватним. Але використовуючи настільки велику часову затримку, ми втрачаємо доволі багато проміжних значень, що також можуть містити досить важливу приховану інформацію для кількісних розрахунків.
delay, parameters = nk.complexity_delay(for_rec,
delay_max=300, show=True,
method="theiler1990")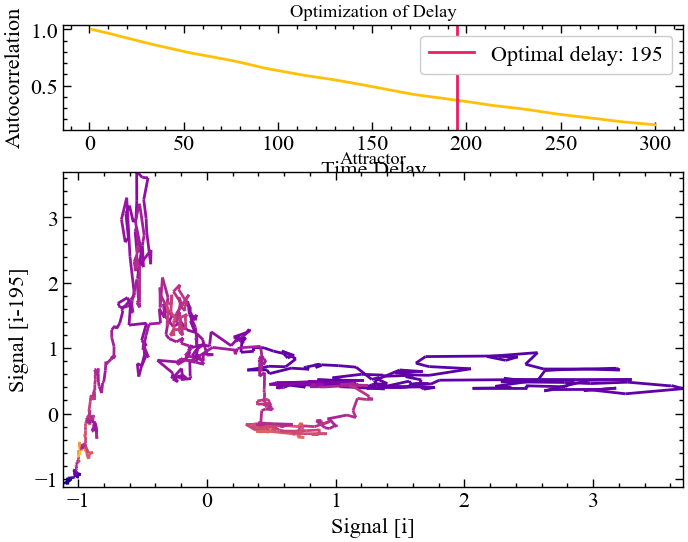
Рис. 2.18 демонструє, що автокореляція між стандартизованих вихідним сигналом Біткоїна та його зміщенною версією при \(\tau=195\) вперше перетинає значення \(1/\exp\). Бачимо, що дане значення затримки є трохи меншим за те, що було отримано до цього, але суті це не змінює. Також бачимо, що між реконструйованими атракторами для \(\tau=195\) та \(\tau=273\) немає кардинальної візуальної різниці.
delay, parameters = nk.complexity_delay(for_rec,
delay_max=500, show=True,
method="casdagli1991")
delayЯк можна бачити по прикладу вище, не всі методи надають адекватну оцінку розмірності нашого сигналу. Спробуємо привести вихідні значення Біткоїна до прибутковостей та повторити процедуру Касдаглі ще раз.
ret_type = 4
ret = transformation(signal, ret_type).flatten()delay, parameters = nk.complexity_delay(ret,
delay_max=300, show=True,
method="casdagli1991")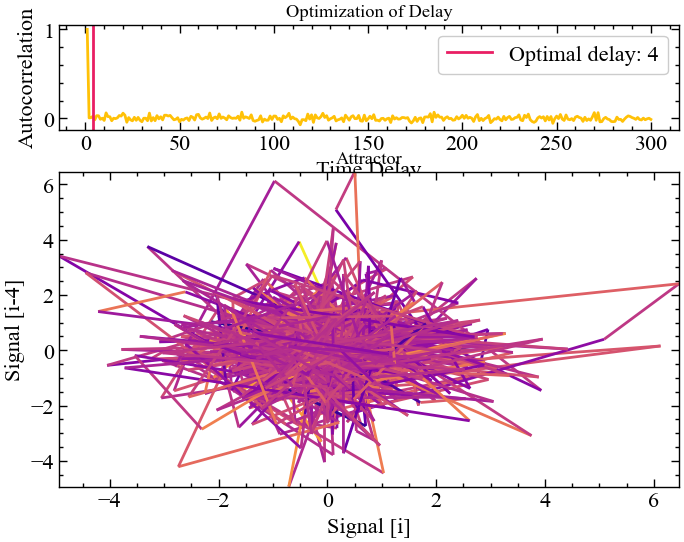
Цього разу нам вдалося досягти оптимального результату, але приклад вище демонструє, що кожна процедура має свої виключення. Рис. 2.19 показує, що значення прибутковостей Біткоїна характеризуються певними кореляціями лише на перших 4-ох лагах. Подальші часові зміщення роблять значення прибутковостей незалежними один від одного.
delay, parameters = nk.complexity_delay(for_rec,
delay_max=300, show=True,
method="rosenstein1993")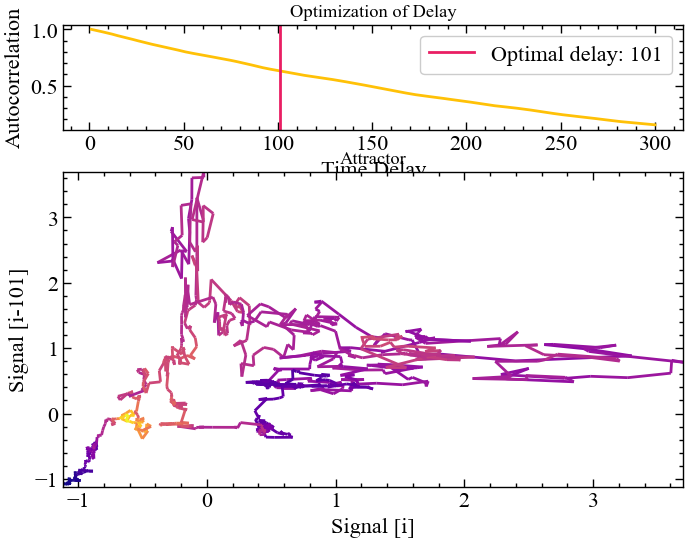
Рис. 2.20 демонструє, що при \(\tau=101\) функція автокореляцій перетинає значення \(\left( 1-1/e \right)\). При цьому видно, що навіть для такого лагу зберігається значна частка кореляцій між стандартизованими вихідними значеннями Біткоїна.
delay, parameters = nk.complexity_delay(for_rec,
delay_max=300, show=True,
method="rosenstein1994")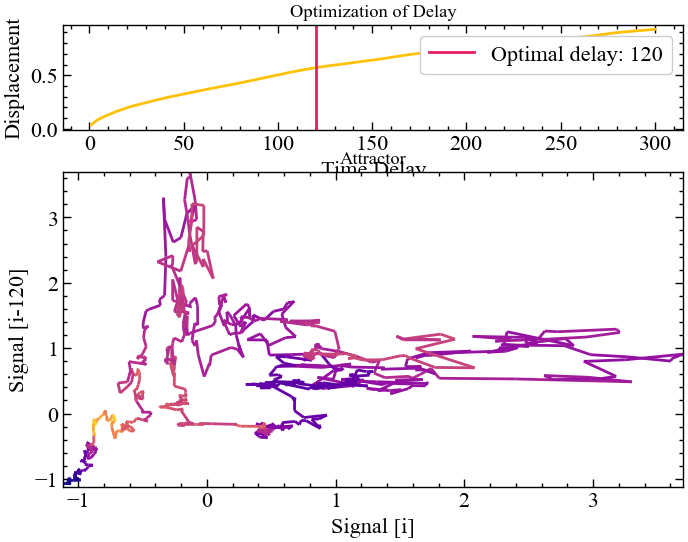
Рисунок вище показує, що при \(\tau=120\) зміщення реконструйованих траєкторій від їх оригінального положення на лінії ідентичності зберігає найбільшу кількість інформації стосовно атрактора стандартизованих значень Біткоїна.
delay, parameters = nk.complexity_delay(for_rec,
delay_max=300, show=True,
method="lyle2021")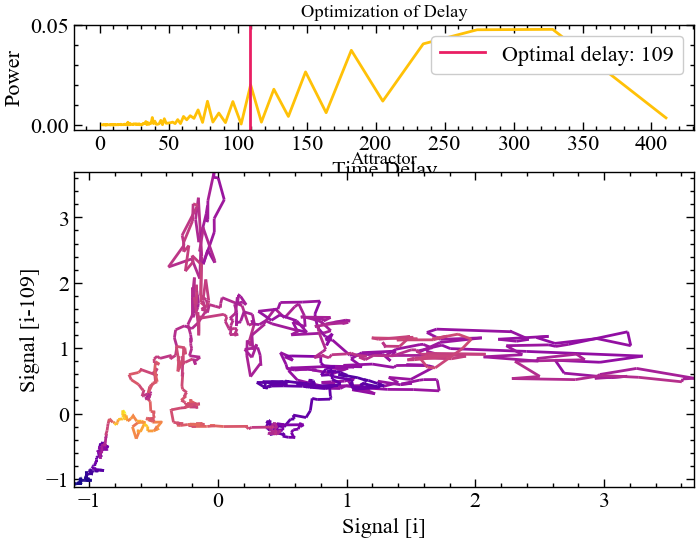
Згідно представленого вище результату найбільш значущі частоти, отримані за допомогою перетворення Фур’є, зберігаються при \(\tau=109\).
Тепер подивимось як це виглядатиме для об’єднаного підбору параметрів:
delay, parameters = nk.complexity_delay(for_rec,
delay_max=np.arange(1, 10, 1), # діапазон значень затримки
dimension_max=10, # максимальна розмірність вкладень
method="gautama2003",
surrogate_n=5, # Кількість сурогатних сигналів
# для генерації
surrogate_method="random", # Спосіб генерації сигналів
show=True)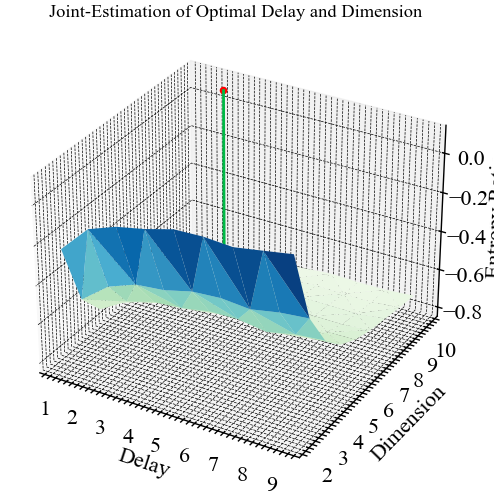
dimension = parameters["Dimension"]
dimension10Оскільки представлена вище процедура є доволі громіздкою в плані обчислювальних потужностей, ми обрали діапазон \(\tau\) в межах від 1 до 10. Видно, що при \(\tau\) близької до 3 оптимальне значення розмірності атрактора дорівнює 10. Можливо, при значеннях \(\tau\) близьких до 100 або 200, ми могли б отримати зовсім інше значення розмірності, але це потребує додаткових експериментів.
2.4.2 Автоматизований підбір параметра розмірності вкладень, \(m\)
За дану процедуру відповідає метод complexity dimension(). Її синтаксис виглядає наступним чином:
complexity_dimension(signal, delay=1, dimension_max=20, method='afnn', show=False, **kwargs)
Хоча зазвичай використовують \(m=2\) або \(m=3\), але різні автори пропонують наступні процедури підбору:
- кореляційна розмірність (Correlation Dimension, CD): Одним з перших методів оцінки оптимального \(m\) був розрахунок кореляційної розмірності для вкладень різного розміру і пошук насичення (тобто плато) в її значенні при збільшенні розміру векторів [16–18]. Одне з обмежень полягає в тому, що насичення буде також мати місце, коли даних недостатньо для адекватного заповнення простору високої розмірності (зауважте, що в загальному випадку не рекомендується мати настільки великі вкладення, оскільки це значно скорочує довжину сигналу);
- найближчі хибні сусіди (False Nearest Neighbour, FNN): Метод, запропонований Кеннелом та ін. [19–21], базується на припущенні, що дві точки, які є близькими одна до одної в достатній розмірності вбудовування, повинні залишатися близькими при збільшенні розмірності. Алгоритм перевіряє сусідів при збільшенні розмірності вкладень, поки не знайде лише незначну кількість хибних сусідів при переході від розмірності \(m\) до \(m+1\). Це відповідає найнижчій розмірності вкладення, яка, як передбачається, дає розгорнуту реконструкцію просторово-часового стану. Цей метод може не спрацювати в зашумлених сигналах через марну спробу розгорнути шум (а в чисто випадкових сигналах кількість хибних сусідів суттєво не зменшується зі збільшенням \(m\)). На рисунку нижче (Рис. 2.24) показано, як проекції на простори більшої розмірності можна використовувати для виявлення хибних найближчих сусідів. Наприклад, червона та жовта точки є сусідами в одновимірному просторі, але не в двовимірному;
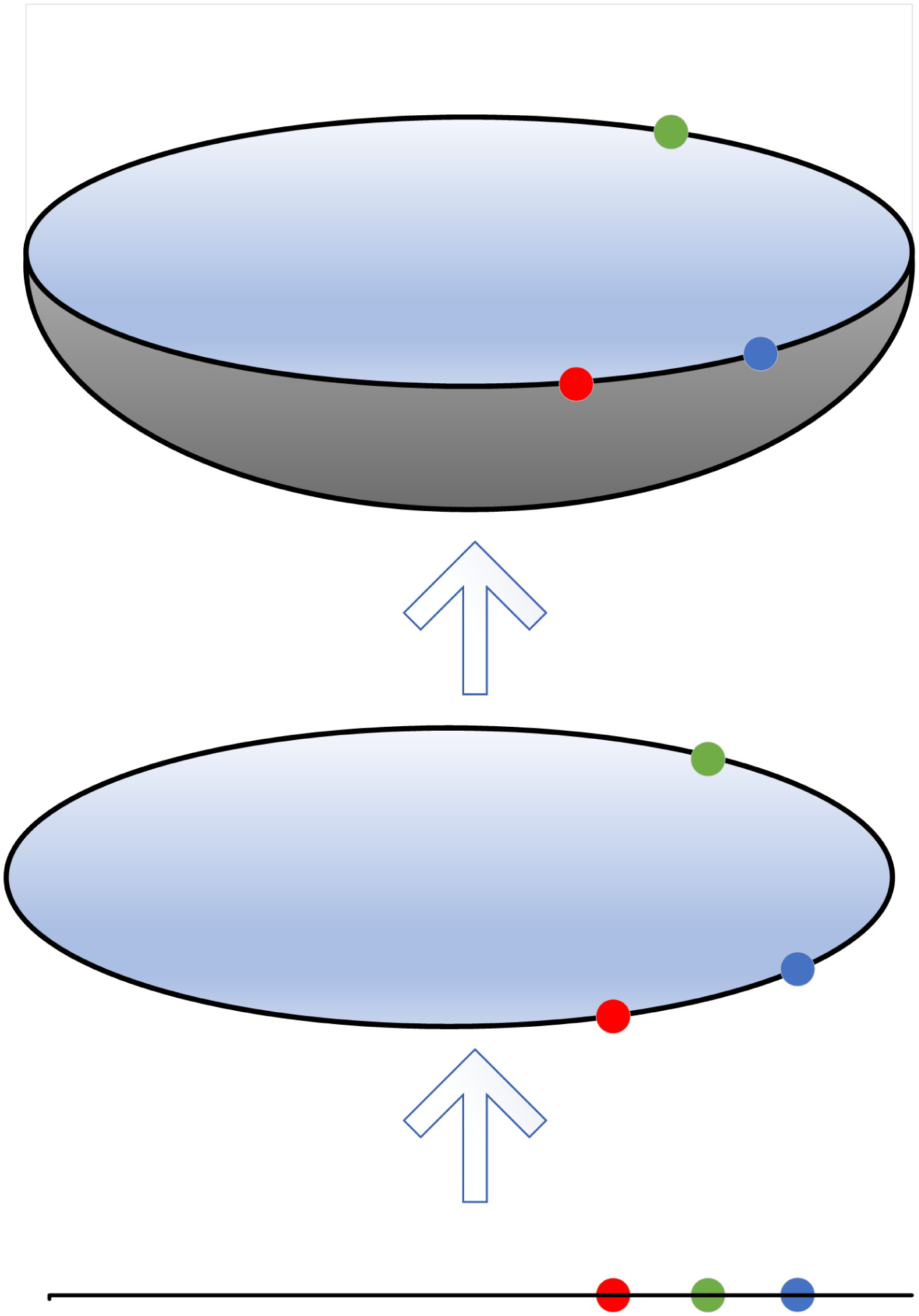
- середні хибні сусіди (Average False Neighbors, AFN): Ця модифікація методу FNN розроблена Сао (1997) [23] і усуває один з його основних недоліків — необхідність евристичного вибору порогових значень \(r\). Метод використовує максимальну евклідову відстань для представлення найближчих сусідів і усереднює всі відношення відстані в \(m+1\) розмірності до розмірності \(m\) та визначає E1 та E2 як параметри. Оптимальна розмірність досягається тоді, коли E1 перестає змінюватися (виходить на плато). Це відбувається при розмірності d0, якщо сигнал надходить від атрактора. Тоді d0+1* є оптимальною мінімальною розмірністю вкладення. E2 є корисною величиною для того, щоб відрізнити детерміновані сигнали від стохастичних. Константа E2, що близька до 1 для будь-якої розмірності вкладень \(d\), вказує на випадковість даних, оскільки майбутні значення не залежать від минулих.
Параметри:
- signal (Union[list, np.array, pd.Series]) — сигнал (тобто часовий ряд) у вигляді вектора значень;
- delay (int) — часова затримка у відліках. Для вибору оптимального значення цього параметра ми ще скористаємось методом
complexity_delay(); - dimension_max (int) — максимальний розмір вкладення для тестування;
- method (str) — може бути
"afn"(середні хибні сусіди),"fnn"(найближчий хибний сусід) або"cd"(кореляційна розмірність); - show (bool) — візуалізувати результат;
- kwargs — інші аргументи, такі як \(R=10.0\) або \(A=2.0\) (відносне та абсолютне граничне значення, тільки для методу
"fnn").
Повертає:
- dimension (int) — оптимальна розмірність вкладень;
- parameters (dict) — словник python, що містить додаткову інформацію про параметри, які використовуються для обчислення оптимальної розмірності.
Спробуємо отримати оптимальне значення розмірності згідно зазначених процедур. В якості часової затримки можна взяти \(\tau=100\). Приблизно таке значення спостерігалося для кожної процедури.
optimal_dimension, info = nk.complexity_dimension(for_rec,
delay=100,
dimension_max=10,
method='cd',
show=True)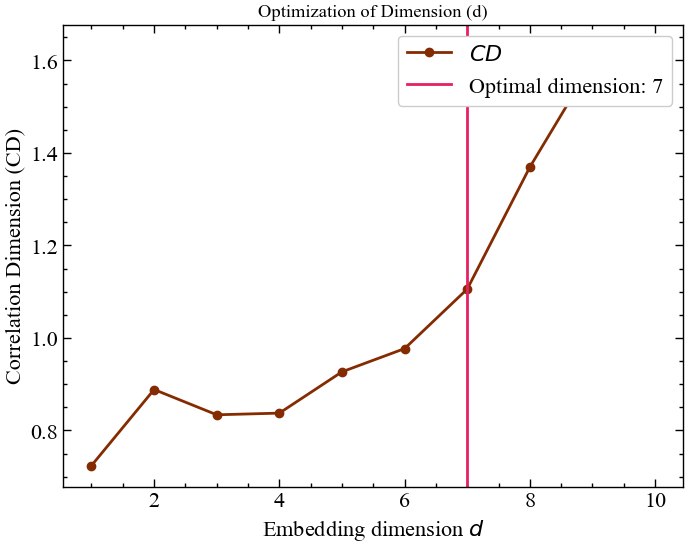
Рис. 2.25 демонструє той факт, що оптимальна розмірність вкладень, за якої досягається найбільш інформативна репрезентація фазового простору, дорівнює 7.
optimal_dimension, info = nk.complexity_dimension(for_rec,
delay=100,
dimension_max=10,
method='fnn',
show=True)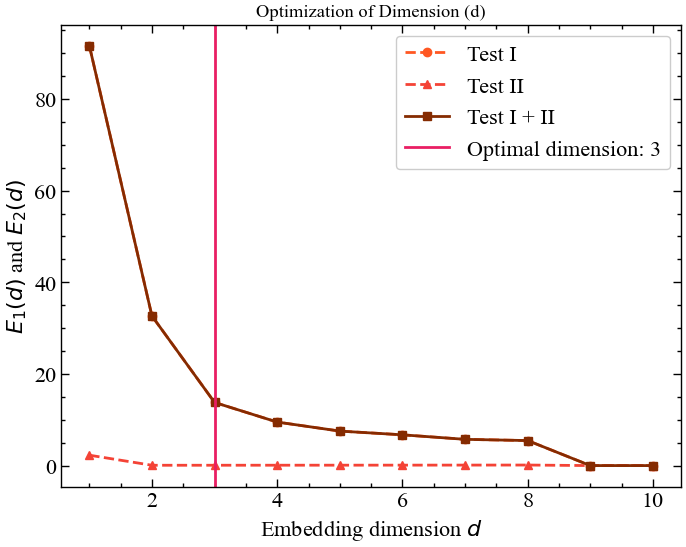
З рисунку 2.26 видно, що мінімальна розмірність вкладення дорівнює 3. Саме при переході від 3-ох вимірного фазового простору до 4-ох вимірного ми бачимо, що кількість хибних сусідів стає мінімальною і далі не зростає.
optimal_dimension, info = nk.complexity_dimension(for_rec,
delay=20,
dimension_max=20,
method='afnn',
show=True)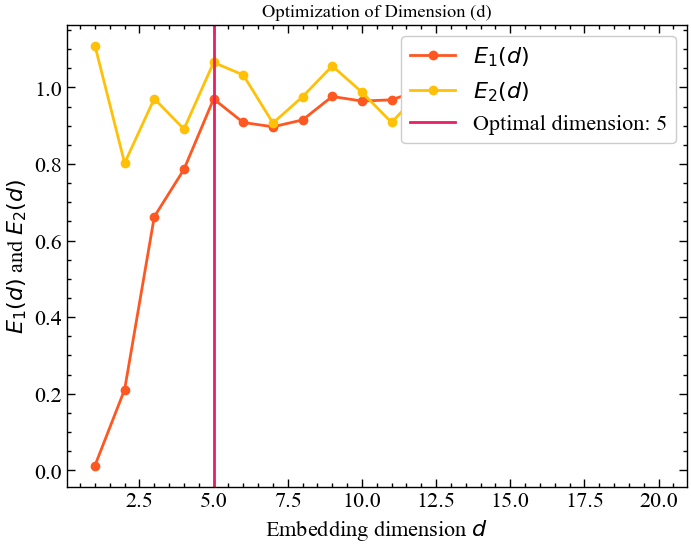
Алгоритм середніх хибних сусідів показує, що тут розмірність вкладень \(m=5\) є оптимальною. При подальшому зростанні розмірності, атрактор стає більш стохастичним, що вказує на втрату всіх кореляцій.
Згідно з представленими вище алгоритмами автоматичного підбору, розмірність вкладень можна обирати в діапазоні значень від 3 до 7. Тепер на основі отриманих результатів приступимо до побудови рекурентної діаграми.