!pip install yfinance --upgrade --no-cache-dir1 Лабораторна робота № 1
Тема. Аналіз флуктуацій часового ряду
Мета. Навчитися використовувати аналіз флуктуацій та його похідні для отримання нелінійних характеристик часового ряду
1.1 Теоретичні відомості
1.1.1 Аналіз динаміки прибутків, модулів прибутків та волатильностей
Останнім часом вчені все більше цікавляться економічними часовими рядами, і відбувається це за кількох причин, зокрема: (1) економічні часові ряди, такі як індекси акцій, курсів валют, залежать від розвитку великої кількості взаємодіючих систем, і є прикладами складних систем, що широко вивчаються у науці; (2) з’явилась велика кількість доступних баз з даними про економічні системи, що містять інформацію з різними часовими шкалами (починаючи з 1 хвилини і закінчуючи 1 роком). Внаслідок цього вже на даний час існує також велика кількість розроблених методів (зокрема, у статистичній фізиці), спрямованих на отримання характеристик цін акцій чи курсів валют, що еволюціонують у часі.
Дослідження, проведені над часовими рядами, показують, що стохастичний процес, який лежить у основі зміни ціни, характеризується кількома ознаками. Розподіл зміни ціни має виділений хвіст порівняно із Гаусовим розподілом. Функція автокореляції зміни ціни спадає експоненційно з певним характерним часом. Однак, виявляється, що амплітуда зміни ціни, виміряна за абсолютними значеннями чи квадратами цін, показує степеневі кореляції з довго часовою персистентністю аж до кількох місяців, або навіть років. Такі довгочасові залежності краще моделюються з використанням “додаткового процесу”, що в економічній літературі часто називається волатильністю. Волатильність змін ціни акції є мірою того, як сильно ринок схильний до флуктуацій, тобто відхилень ціни від попередніх значень.
Першим кроком при проведенні аналізу є побудова оцінювача волатильності. Ми будемо отримувати волатильність як локальне середнє модуля зміни ціни.
Розуміння статистичних властивостей волатильності має також важливе практичне застосування. Волатильність є інтересом торговців, оскільки визначає ризик і є ключовим входом практично до всіх моделей цін опціонів (вторинного цінного паперу), включаючи і класичну модель Блека-Шоулза. Без задовільних методів оцінювання волатильності трейдерам було б надзвичайно важко визначати ситуації, в яких опціони попадають в недооцінку чи переоцінку.
1.1.2 Визначення волатильності
Термін волатильність представляє узагальнену міру величини ринкових флуктуацій (відхилень). У літературі існує досить багато визначень волатильності, проте ми будемо використовувати наступне: волатильність є локальним середнім модуля зміни ціни на відповідному часовому інтервалі \(T\), що є рухомим параметром нашої оцінки. Для індексу \(X(t)\) визначимо зміну ціни \(G(t)\) як зміну логарифмів індексів,
\[ G(t) = \ln{X(t+\Delta t) - \ln{X(t)}} \cong \left[ X(t+\Delta t) - X(t) \right] \big/ X(t), \tag{1.1}\]
де \(\Delta t\) є часовим інтервалом затримки. Величину (1.1) називають прибутковістю (return). Якщо використовувати границі, то малі зміни \(X(t)\) приблизно відповідають змінам, визначеним другою рівністю. Ми лише підраховуємо час роботи ринку, викидаємо ночі, вихідні та свята із набору даних, тобто, вважаємо, що ринок працює без перерв.
Модуль \(G(t)\) описує амплітуду флуктуацій. У порівнянні зі значеннями \(G(t)\) їх модуль не показує глобальних трендів, але великі значення \(G(t)\) відповідають крахам та великим миттєвим змінам на ринках.
Визначимо волатильність як середнє від \(G(t)\) для часових вікон \(T = n \cdot \Delta t\), тобто
\[ V_{T} = \frac{1}{n}\sum_{t^{'}=t}^{t+n-1}\left| G(t^{'}) \right|, \tag{1.2}\]
де \(n\) є цілим числом. Таке визначення може бути ще узагальнене заміною \(G(t)\) на \(\left| G(t) \right|^{\gamma}\), де \(\gamma > 1\) дає більш виражені великі значення \(G(t)\), в той час як \(0 < \gamma < 1\) виділяє малі значення \(G(t)\).
У цьому визначенні волатильності використовується два параметри: \(\Delta t\) та \(n\). Параметр \(n\) є шаблонним (чи модельним) часовим інтервалом для даних, а параметр \(\Delta t\) є кроком переміщення часового вікна. Зауважимо, що вказане визначення волатильності має внутрішню помилку, а саме: вибір більшого часового інтервалу \(T\) веде до збільшення точності визначення волатильності. Однак, велике значення \(T\) також включає погане розбиття часу на інтервали, що веде, у свою чергу, до врахування не всієї прихованої у ряді інформації.
1.1.3 Визначення кореляцій
Для визначення кореляцій часового ряду використовується функція автокореляції. Саме поняття автокореляції означає кореляцію часового ряду самого з собою (між попередніми та наступними значеннями). Автокореляцію іноді називають послідовною кореляцією, що означає кореляцію між членами ряду чисел, розташованих у певному порядку. Також синонімами цього терміну є лагова кореляція та персистентність. Наприклад, часто зустрічається автокореляція геофізичних процесів, що означає перенесення залишкового процесу на наступні часові проміжки.
Позитивно автокорельований часовий ряд часто називають персистентним, що значить існування тенденції слідування великих значень за великими та малих за малими, інакше позитивно корельований часовий ряд можна назвати інертним.
Візьмемо \(N\) пар спостережень двох змінних \(x\) та \(y\). Коефіцієнт кореляції між парами \(x\) та \(y\) визначається як
\[ r = \left[ \sum \left( x_i - \bar{x} \right) \left( y_i - \bar{y} \right) \right] \Bigg/ \left[ \sqrt{\sum \left( x_i - \bar{x} \right)^{2}} \sqrt{\sum \left( y_i - \bar{y} \right)^{2}} \right], \tag{1.3}\]
де сума знаходиться за всіма \(N\) спостереженням.
Таким же чином можна визначати й автокореляцію, або ж кореляцію всередині досліджуваного часового ряду. Для автокореляції першого порядку береться лаг (часова затримка), рівний 1 часовій одиниці. Отже, автокореляція першого порядку використовує перші \(N−1\) спостережень \(x_t, t = 1,..., N−1\) та наступні \(N−1\) спостережень \(x_t , t = 2,..., N\).
Кореляція між \(x_t\) та \(x_t + 1\) визначається як
\[ r_1 = \left[ \sum_{t=1}^{N-1} \left( x_t - \bar{x} \right) \left( x_{t+1} - \bar{x} \right) \right] \Bigg/ \left[ \sum_{t=1}^{N}\left( x_t - \bar{x} \right)^2 \right], \tag{1.4}\]
де \(x\) — це середнє для досліджуваного періоду.
Рівняння (1.4) може бути узагальнене для отримання кореляції між спостереженнями, розділеними \(k\) часовими інтервалами:
\[ r_k = \left[ \sum_{t=1}^{N-k} \left( x_t - \bar{x} \right) \left( x_{t+k} - \bar{x} \right) \right] \Bigg/ \left[ \sum_{t=1}^{N}\left( x_t - \bar{x} \right)^2 \right]. \tag{1.5}\]
Значення \(r_k\) називається коефіцієнтом автокореляції з лагом \(k\). Графік функції автокореляції як залежності \(r_k\) від \(k\) також називають корелограмою.
1.2 Хід роботи
Для подальшої роботи з моделювання складних систем візьмемо з основу бібліотеку yfinance, що дозволяє працювати з даними фінансових ринків засобами мови програмування Python.
Примітка
Yahoo!, Y!Finance, and Yahoo! finance є зареєстрованими товарними знаками Yahoo, Inc.
yfinance не є афілійованим, схваленим або перевіреним Yahoo, Inc. Це інструмент з відкритим вихідним кодом, який використовує загальнодоступні API Yahoo, і призначений для дослідницьких та освітніх цілей.
Ви повинні звернутися до умов використання Yahoo! (сюди, сюди і сюди) для отримання детальної інформації про ваші права на використання фактично завантажених даних. Пам’ятайте — фінансовий API Yahoo! призначений лише для особистого використання
Для встановлення бібліотеки yfinance можете скористатися наступною командою:
Гітхаб репозиторій містить більше інформації по самій бібліотеці та помилкам, що можуть виникнути та їх потенційним рішенням.
1.2.1 Вступ до модуля Ticker()
Перш за все імпортуємо бібліотеку yfinance за допомогою наступної команди:
import yfinance as yfМодуль Ticker() дозволяє отримувати ринкові та метадані для цінного паперу, використовуючи Python:
msft = yf.Ticker("MSFT")
print(msft)yfinance.Ticker object <MSFT>Можна вилучити всю інформацію по досліджуваному індексу:
# отримати інформацію по індексу
msft.infoМожна вилучити ринкові значення за максимальний період часу:
# отримати ринкові історичні значення індексу
msft.history(period="max")| Open | High | Low | Close | Volume | Dividends | Stock Splits | |
|---|---|---|---|---|---|---|---|
| Date | |||||||
| 1986-03-13 00:00:00-05:00 | 0.054376 | 0.062373 | 0.054376 | 0.059707 | 1031788800 | 0.0 | 0.0 |
| 1986-03-14 00:00:00-05:00 | 0.059707 | 0.062906 | 0.059707 | 0.061839 | 308160000 | 0.0 | 0.0 |
| 1986-03-17 00:00:00-05:00 | 0.061839 | 0.063439 | 0.061839 | 0.062906 | 133171200 | 0.0 | 0.0 |
| 1986-03-18 00:00:00-05:00 | 0.062906 | 0.063439 | 0.060773 | 0.061306 | 67766400 | 0.0 | 0.0 |
| 1986-03-19 00:00:00-05:00 | 0.061306 | 0.061839 | 0.059707 | 0.060240 | 47894400 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 2025-03-25 00:00:00-04:00 | 393.920013 | 396.359985 | 392.640015 | 395.160004 | 15775000 | 0.0 | 0.0 |
| 2025-03-26 00:00:00-04:00 | 395.000000 | 395.309998 | 388.570007 | 389.970001 | 16108400 | 0.0 | 0.0 |
| 2025-03-27 00:00:00-04:00 | 390.130005 | 392.239990 | 387.399994 | 390.579987 | 13766800 | 0.0 | 0.0 |
| 2025-03-28 00:00:00-04:00 | 388.079987 | 389.130005 | 376.929993 | 378.799988 | 21632000 | 0.0 | 0.0 |
| 2025-03-31 00:00:00-04:00 | 372.540009 | 377.070007 | 367.239990 | 375.390015 | 35158100 | 0.0 | 0.0 |
9839 rows × 7 columns
Окрім цього, yfinance дозволяє отримати інформацію по дивідентам та сплітам фінансового індексу:
# показувати дії (дивіденди, спліти)
msft.actions| Dividends | Stock Splits | |
|---|---|---|
| Date | ||
| 1987-09-21 00:00:00-04:00 | 0.00 | 2.0 |
| 1990-04-16 00:00:00-04:00 | 0.00 | 2.0 |
| 1991-06-27 00:00:00-04:00 | 0.00 | 1.5 |
| 1992-06-15 00:00:00-04:00 | 0.00 | 1.5 |
| 1994-05-23 00:00:00-04:00 | 0.00 | 2.0 |
| ... | ... | ... |
| 2024-02-14 00:00:00-05:00 | 0.75 | 0.0 |
| 2024-05-15 00:00:00-04:00 | 0.75 | 0.0 |
| 2024-08-15 00:00:00-04:00 | 0.75 | 0.0 |
| 2024-11-21 00:00:00-05:00 | 0.83 | 0.0 |
| 2025-02-20 00:00:00-05:00 | 0.83 | 0.0 |
94 rows × 2 columns
# продемонструвати дивіденти
msft.dividendsDate
2003-02-19 00:00:00-05:00 0.08
2003-10-15 00:00:00-04:00 0.16
2004-08-23 00:00:00-04:00 0.08
2004-11-15 00:00:00-05:00 3.08
2005-02-15 00:00:00-05:00 0.08
...
2024-02-14 00:00:00-05:00 0.75
2024-05-15 00:00:00-04:00 0.75
2024-08-15 00:00:00-04:00 0.75
2024-11-21 00:00:00-05:00 0.83
2025-02-20 00:00:00-05:00 0.83
Name: Dividends, Length: 85, dtype: float64# продемонструвати спліти
msft.splitsDate
1987-09-21 00:00:00-04:00 2.0
1990-04-16 00:00:00-04:00 2.0
1991-06-27 00:00:00-04:00 1.5
1992-06-15 00:00:00-04:00 1.5
1994-05-23 00:00:00-04:00 2.0
1996-12-09 00:00:00-05:00 2.0
1998-02-23 00:00:00-05:00 2.0
1999-03-29 00:00:00-05:00 2.0
2003-02-18 00:00:00-05:00 2.0
Name: Stock Splits, dtype: float64Для методу history() доступні аргументи:
- period: період даних для завантаження (або використовуйте параметр period, або використовуйте start і end). Допустимі періоди: 1d, 5d, 1mo, 3mo, 6mo, 1y, 2y, 5y, 10y, ytd, max;
- interval: інтервал даних (внутрішньоденні дані не можуть перевищувати 60 днів) Допустимі інтервали 1m, 2m, 5m, 15m, 30m, 60m, 90m, 1h, 1d, 5d, 1wk, 1mo, 3mo;
- start: Якщо не використовується період — завантажте рядок дати початку у форматі (YYYY-MM-DD) або datetime;
- end: Якщо не використовується період — завантажте рядок дати закінчення (YYYY-MM-DD) або datetime;
- prepost: Включати в результати попередні та пост ринкові дані (За замовчуванням False);
- auto_adjust: Автоматично налаштовувати всі OHLC (ціни відкриття, закриття, найбільшу та найменшу) (За замовчуванням True);
- actions: Завантажувати події дивідендів та дроблення акцій (За замовчуванням True).
1.2.2 Одночасне вивантаження декількох ринкових активів
Як і до цього, ви також можете завантажувати дані для кількох тикерів одночасно:
data = yf.download("SPY AAPL",
start="2017-01-01",
end="2017-04-30") # вивантажуємо дані,
# зберігаємо до змінної data
data.head() # виводимо перші 5 рядків нашого масиву данихYF.download() has changed argument auto_adjust default to True[*********************100%***********************] 2 of 2 completed| Price | Close | High | Low | Open | Volume | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ticker | AAPL | SPY | AAPL | SPY | AAPL | SPY | AAPL | SPY | AAPL | SPY |
| Date | ||||||||||
| 2017-01-03 | 26.862429 | 196.697159 | 26.904058 | 197.212390 | 26.540959 | 195.509500 | 26.781483 | 196.522493 | 115127600 | 91366500 |
| 2017-01-04 | 26.832361 | 197.867340 | 26.945687 | 198.015796 | 26.769918 | 197.020259 | 26.793045 | 197.028987 | 84472400 | 78744400 |
| 2017-01-05 | 26.968811 | 197.710114 | 27.026629 | 197.867310 | 26.783791 | 196.906699 | 26.809232 | 197.596596 | 88774400 | 78379000 |
| 2017-01-06 | 27.269466 | 198.417465 | 27.327285 | 198.889029 | 26.936432 | 197.273460 | 27.008126 | 197.823629 | 127007600 | 71559900 |
| 2017-01-09 | 27.519241 | 197.762543 | 27.621002 | 198.295243 | 27.276405 | 197.727604 | 27.278717 | 198.155515 | 134247600 | 46939700 |
Для отримання конкретно цін закриття індексу SPY вам варто використовувати наступну команду: data['Close']['SPY'] Але, якщо вам необхідно згрупувати дані за їх символом, можна скористатися наступним записом:
data = yf.download("SPY AAPL",
start="2017-01-01",
end="2017-04-30",
group_by="ticker")[*********************100%***********************] 2 of 2 completedТепер для звернення до цін закриття індексу SPY вам треба використовувати наступний запис: data['SPY']['Close'].
Метод download() приймає додатковий параметр threads для швидшої обробки великої кількості фінансових індексів одночасно.
Для подальшої роботи нас ще будуть цікавати наступні бібліотеки:
matplotlib: комплексна бібліотека для створення статичних, анімованих та інтерактивних візуалізацій на Python. Matplotlib робить прості речі простими, а складні — можливими;pandas: програмна бібліотека написана для мови програмування Python для маніпулювання та аналізу даних. Зокрема, вона пропонує структури даних та операції з числовими таблицями та часовими рядами;numpy: бібліотека, що додає підтримку великих багатовимірних масивів і матриць, а також колекцію високорівневих математичних функцій для роботи з цими масивами;neurokit2: зручна бібліотека, що забезпечує легкий доступ до розширених процедур обробки біосигналів. Дослідники та клініцисти без глибоких знань програмування або біомедичної обробки сигналів можуть аналізувати фізіологічні дані за допомогою лише двох рядків коду. Перевага даної бібліотеки полягає в тому, що вона надає функціонал, який можна використовувати не лише для біомедичних сигналів, але й для фінансових, фізичних тощо.
Встановити кожну з даних бібліотек можна в наступний спосіб: !pip install *назва бібліотеки*:
!pip install matplotlib pandas numpy neurokit2Далі нам треба буде визначити стиль рисунків для виведення та збереження. Встановимо наступну бібліотеку:
# для встановлення останньої версії (із PyPI)
!pip install SciencePlotsІмпортуємо кожну із зазначених бібліотек:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import neurokit2 as nk
import scienceplots
# магічна команда для вбудування рисунків у середовище jupyter блокнотів
%matplotlib inlineВиконаємо налаштування стилю наших подальших рисунків:
plt.style.use(['science', 'notebook', 'grid']) # стиль, що використовуватиметься
# для виведення рисунків
size = 16
params = {
'figure.figsize': (8, 6), # встановлюємо ширину та висоту рисунків за замовчуванням
'font.size': size, # розмір фонтів рисунку
'lines.linewidth': 2, # товщина ліній
'axes.titlesize': 'small', # розмір титулки над рисунком
'axes.labelsize': size, # розмір підписів по осям
'legend.fontsize': size, # розмір легенди
'xtick.labelsize': size, # розмір розмітки по осі Ох
'ytick.labelsize': size, # розмір розмітки по осі Ох
"font.family": "Serif", # сімейство стилів підписів
"font.serif": ["Times New Roman"], # стиль підпису
'savefig.dpi': 300, # якість збережених зображень
'axes.grid': False # побудова сітки на самому рисунку
}
plt.rcParams.update(params) # оновлення стилю згідно налаштуваньПредставлені налаштування є орієнтовними і можуть змінюватись у ході наступних лабораторних роботах. Ви можете встановлювати власні налаштування. На сайті бібліотеки matplotlib можна ознайомитись з усіма можливими командами.
Розглянемо можливість використання всіх згаданих показників у якості індикаторів або індикаторів-передвісників кризових явищ. Для прикладу завантажимо часовий ряд Біткоїна за період з 1 вересня 2015 по 1 березня 2020, використовуючи yfinance:
symbol = 'BTC-USD' # Символ індексу
start = "2015-09-01" # Дата початку зчитування даних
end = "2020-03-01" # Дата закінчення зчитування даних
data = yf.download(symbol, start, end) # вивантажуємо дані
time_ser = data['Close'].copy() # зберігаємо саме ціни закриття
xlabel = 'time, days' # підпис по вісі Ох
ylabel = symbol # підпис по вісі Оу[*********************100%***********************] 1 of 1 completed
Важливо
Представлені в подальшому методи є універсальними. Іншими словами, ви можете їх використовувати не лише для фінансових часових рядів, але й для біологічних, фізичних та інших систем, що існують в осяжній нами реальності та можуть бути репрезентовані у вигляду часового ряду. Може бути так, що наявні у вас дані, наприклад, представлені у форматі текстового документа (.txt). Нижче представлено приклад зчитування текстового файлу, що представляє залежність між напруженням і деформацією твердого тіла. Представлену далі залежність було отримано в результаті механічних випробувань певного металу. Зрозуміло, що аналіз результатів і висновки у цьому випадку залежать від того, з яким рядом ми працюємо
symbol = 'sMpa11' # Символ індексу
path = "databases\\sMpa11.txt" # шлях по якому здійснюється зчитування файлу
data = pd.read_csv(path, # зчитування даних
names=[symbol])
time_ser = data[symbol].copy() # копіюємо значення кривої
# "напруга-видовження" до окремої змінної
xlabel = r'$\varepsilon$' # підпис по вісі Ох
ylabel = symbol # підпис по вісі ОуТепер виведемо значення, що були зчитані з текстового документа:
fig, ax = plt.subplots(1, 1) # Створюємо порожній графік
ax.plot(time_ser.index, time_ser.values) # Додаємо дані до графіку
ax.legend([symbol]) # Додаємо легенду
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
plt.xticks(rotation=45) # оберт позначок по осі Ох на 45 градусів
plt.savefig(f'{symbol}.jpg') # Зберігаємо графік
plt.show(); # Виводимо графік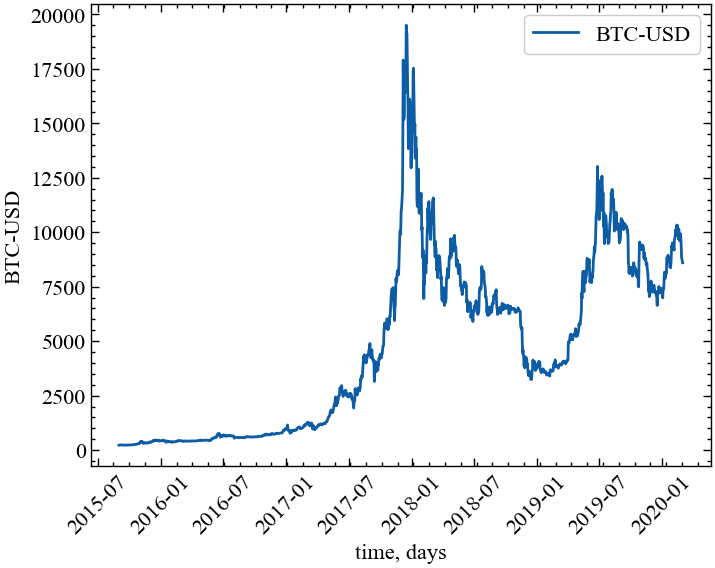
Для даного ряду, за потребою, можна виконувати подальші розрахунки.
Увага
Знову повертаємось до Біткоїна. Для відтворення подальших розрахунків з Біткоїном блок коду в якому зчитувалась та виводилась крива “напруга-видовження” треба проігнорувати
Виведемо значення Біткоїна:
fig, ax = plt.subplots(1, 1) # Створюємо порожній графік
ax.plot(time_ser.index, time_ser.values) # Додаємо дані до графіку
ax.legend([symbol]) # Додаємо легенду
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
plt.xticks(rotation=45) # оберт позначок по осі Ох на 45 градусів
plt.savefig(f'{symbol}.jpg') # Зберігаємо графік
plt.show(); # Виводимо графік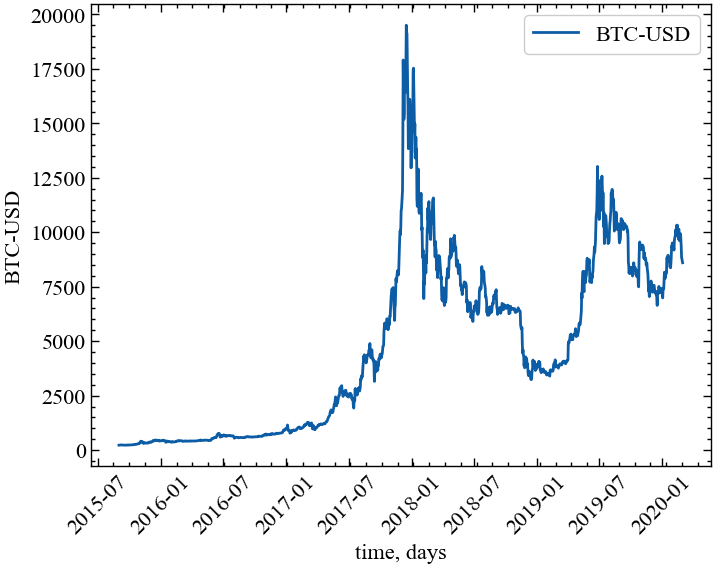
Видно, що ряд нестаціонарний, що викликає певні ускладнення для подальшого аналізу. Тому перейдемо до прибутковостей, які вже є стаціонарними, а нормалізація стандартним відхиленням дозволяє легко порівнювати їх розподіл з розподілом Гауса.
Прибутковості розраховуватимуться згідно рівняння (1.1). У Python для цього ми використовуватимемо метод pct_change(), що доступний нам завдяки бібліотеці pandas.
Стандартизовані прибутковості можна визначити як \(g(t) = \left[G(t) - \mu \right] / \sigma\), де \(\mu\) відповідає середньому значенню прибутковостей за досліджуваний часовий інтервал, а \(\sigma\) представляє стандартне відхилення.
ret = time_ser.copy() # копіюємо значення вихідного ряду для збереження
# його від змін
ret = ret.pct_change() # знаходимо прибутковості
ret -= ret.mean() # вилучаємо середнє
ret /= ret.std() # ділимо на стандартнє відхилення
ret = ret.dropna().values # видаляємо всі можливі нульові значенняВиводимо отриманий результат:
fig, ax = plt.subplots() # Створюємо порожній графік
ax.plot(time_ser.index[1:], ret) # Додаємо дані до графіку
ax.legend([symbol]) # Додаємо легенду
ax.set_xlabel(xlabel) # Додаємо підпис для вісі Ох
ax.set_ylabel(ylabel + ' прибутковості') # Додаємо підпис для вісі Оу
ax.axhline(y = 3.0,
color = 'r',
linestyle = '--') # Додаємо горизонтальну лінію,
# що роз межує 3 сигма події
ax.axhline(y = -3.0,
color = 'r',
linestyle = '--') # Додаємо горизонтальну лінію,
# що розмежує -3 сигма події
plt.xticks(rotation=45) # оберт позначок по осі Ох на 45 градусів
plt.savefig(f'Прибутковості {symbol}.jpg') # Зберігаємо графік
plt.show(); # Виводимо графік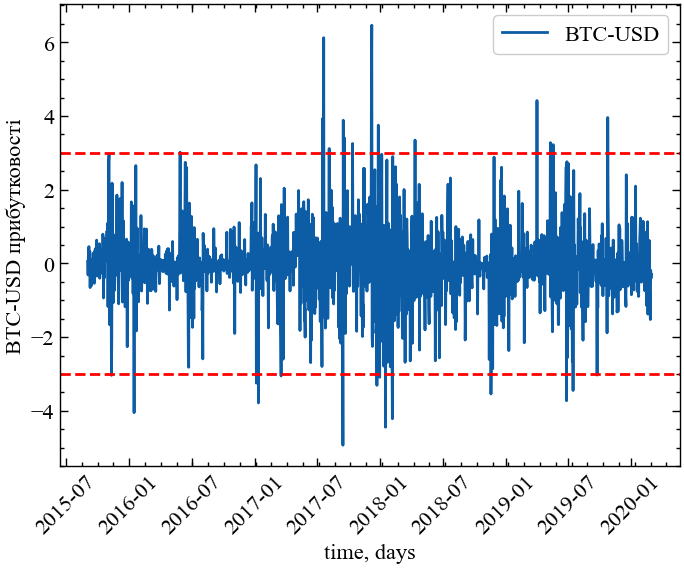
Зверніть увагу, що флуктуації нормалізованих прибутковостей досить часто перевищують величину \(\pm 3\sigma\), що, як відомо, надзвичайно рідко спостерігається для незалежних подій. Цей факт можна відобразити шляхом порівняння функції розподілу нормалізованих флуктуацій з розподілом Гауса (Рис. 1.4). Очевидно, що хвости розподілу вихідного ряду містять значні флуктуації, вони досить помітні (часто кажуть “важкі” у порівнянні з самою “головою” розподілу).
Для побудови нормального розподілу скористаємось бібліотекою scipy. Встановити її можна за аналогією з попередніми бібліотеками.
# Для встановлення останньої версії scipy
!pip install scipyfrom scipy.stats import norm # імпорт модуля norm для побудови Гаусового розподілуФункція щільності ймовірності norm для дійсних значень \(x\) має наступний вигляд: \(f(x) = \exp{(-x^2/2)} \big/ \sqrt{2\pi}\).
mu, sigma = norm.fit(ret)
x = np.linspace(ret.min(), ret.max(), 10000) # Генеруємо 10000 значень для побудови
# Гаусового розподілу
p = norm.pdf(x, mu, sigma) # Отримання значень функції щільностіfig, ax = plt.subplots(1, 1) # Створюємо порожній графік
ax.plot(x, p, label='Гаусіан') # Додаємо дані до графіку
ax.hist(ret, bins=50, # Побудова гістограми для прибутковостей
density=True,
alpha=0.6,
color='g',
label='Прибутковості '+ symbol)
ax.legend() # Додаємо легенду
ax.set_xlabel("g") # Додаємо підпис для вісі Ох
ax.set_ylabel(r"$f(g)$") # Додаємо підпис для вісі Оу
ax.set_yscale('log')
plt.savefig(f'Гаус + прибутковості {symbol}.jpg') # Зберігаємо графік
plt.show(); # Виводимо графік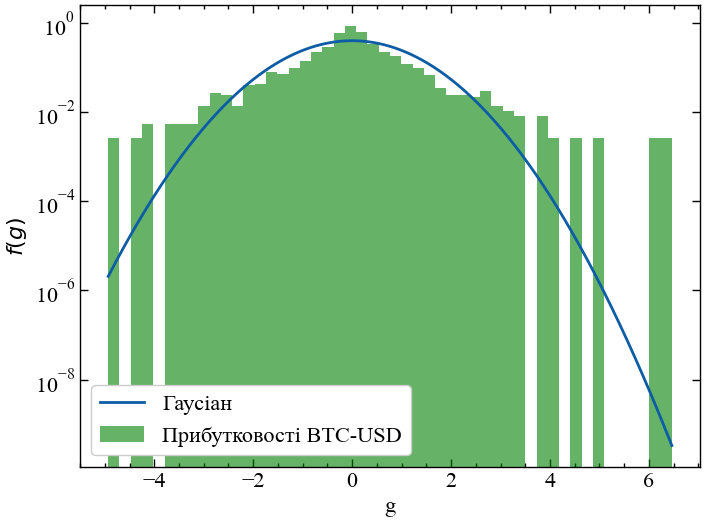
Як ми можемо бачити, крива Гауса відхиляється від істинної частоти настання подій, що перевищують \(\pm 3\sigma\), і ми можемо стверджувати, що прибутковості не є незалежними. Підтвердження цьому факту будемо шукати шляхом вивчення кореляційних властивостей нашого часового ряду.
Для простоти обчислень скористаємось функцією signal_autocor() бібліотеки neurokit2. Виглядає дана функція наступним чином:
signal_autocor(signal, lag=None, demean=True, method='auto', show=False)
Параметри:
- signal (Union[list, np.array, pd.Series]) — вектор значень;
- lag (int) — часовий лаг. Якщо вказано, буде повернуто одне значення автокореляції сигналу з його власним лагом;
- demean (bool) — якщо має значення
True, від сигналу буде відніматися середнє значення сигналу перед обчисленням автокореляції; - method (str) — використання
"auto"запускаєscipy.signal.correlateшвидшого алгоритму. Інші методи зберігаються з причин застарілості, але не рекомендуються. Вони включають"correlation"(за допомогоюnp.correlate()) або"fft"(швидке перетворення Фур’є); - show (bool) — якщо значення
True, побудувати графік автокореляції для всіх значень затримки.
Повертає:
- r (float) — крос-кореляція сигналу із самим собою на різних часових лагах. Мінімальний часовий лаг дорівнює 0, максимальний часовий лаг дорівнює довжині сигналу. Або значення кореляції на певному часовому лазі, якщо лаг не дорівнює
None; - info (dict) — cловник, що містить додаткову інформацію, наприклад, довірчий інтервал.
len(time_ser.values)1643# розрахунок автокореляції
r_init, _ = nk.signal_autocor(time_ser.values.flatten(),
method='correlation') # для вихідних значень ряду
r_ret, _ = nk.signal_autocor(ret.flatten(),
method='correlation') # для прибутковостей
r_vol, _ = nk.signal_autocor(np.abs(ret.flatten()),
method='correlation') # для модулів прибутковостей
r_range = np.arange(1, len(r_ret) + 1) # генерація лагівfig, ax = plt.subplots(1, 1) # Створюємо порожній графік
ax.plot(r_range, r_init[1:], label=symbol) # Додаємо дані до графіку
ax.plot(r_range, r_ret, label=r'$g(t)$')
ax.plot(r_range, r_vol, label=r'$V_{T}$')
ax.legend() # Додаємо легенду
ax.set_xlabel(r"Часовий лаг $k$") # Додаємо підпис для вісі Ох
ax.set_ylabel(r"Автокореляція $r$") # Додаємо підпис для вісі Оу
ax.set_ylim(-1.1, 1.1) # Встановлюємо обмеження по вісі Oy
plt.savefig(f'Автокореляції {symbol}.jpg') # Зберігаємо графік
plt.show(); # Виводимо графік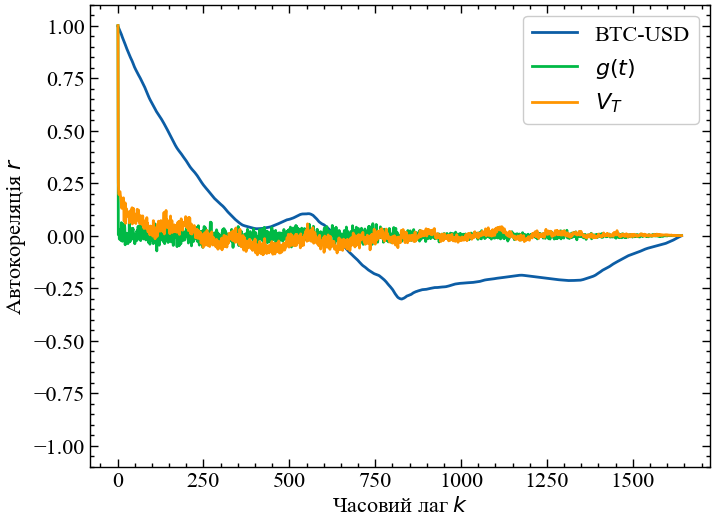
Але, досліджуючи складні системи, варто пам’ятати, що їх складність є варіативною. Тому і внутрішні кореляції системи на різних часових лагах також варіюються з плином часу. Із цього випливає, що подальщі розрахунки варто виконувати не для всього ряду, а для його фрагментів.
Сформулюємо алгоритм ковзного (рухомого) вікна. Виділимо фрагмент часового ряду (вікно), розрахуємо необхідні міри складності, змістимо вікно вздовж часового ряду на заздалегідь визначену величину (крок) і повторимо процедуру до вичерпання часового ряду. Далі, порівнюючи динаміку фактичного часового ряду і відповідних мір складності, ми матимемо змогу судити про характерні зміни в динаміці міри складності зі зміною досліджуваної системи. Якщо та чи інша міра складності поводиться характерним чином для всіх особливих періодів (наприклад, крахів), зменшується або збільшується у передкризовий період, то вона може служити їх індикатором або передвісником.
Розглянемо як поводитиме себе функція автокореляцій та волатильність в рамках алгоритму ковзного вікна.
Спочатку визначимо параметри:
ret_type = 4 # вид ряду:
# 1 - вихідний,
# 2 - детрендований (різниця між теп. значенням та попереднім)
# 3 - прибутковості звичайні,
# 4 - стандартизовані прибутковості,
# 5 - абсолютні значення (волатильності),
# 6 - стандартизований вихідний ряд
length = len(time_ser) # довжина всього ряду
window = 250 # довжина вікна - період у межах якого розраховуватимуться наші індикатори
tstep = 1 # крок зміщення вікна
volatility = [] # масив значень волатильностей
autocorr = [] # масив значень автокореляції при змінній lagДалі розпочнемо розрахунки. Для відслідковування прогресу зміщення ковзного вікна скористаємось бібліотекою tqdm. Її можна встановити аналогічно попереднім бібліотекам:
!pip install tqdmІмпортуємо модуль для візуалізації прогресу:
from tqdm import tqdmІ тепер приступимо до виконання віконної процедури:
for i in tqdm(range(0,length-window,tstep)): # Фрагменти довжиною window
# з кроком tstep
fragm = time_ser.iloc[i:i+window].copy() # відбираємо фрагмент
# подальшому відбираємо потрібний тип ряду
if ret_type == 1: # вихідні значення
pass
elif ret_type == 2: # різниці
fragm = fragm[1:] - fragm[:-1]
elif ret_type == 3: # прибутковості
fragm = fragm.pct_change()
elif ret_type == 4: # стандартизовані прибутковості
fragm = fragm.pct_change()
fragm -= fragm.mean()
fragm /= fragm.std()
elif ret_type == 5: # абсолютні значення прибутковостей
fragm = fragm.pct_change()
fragm -= fragm.mean()
fragm /= fragm.std()
fragm = fragm.abs()
elif ret_type == 6: # стандартизований вихідний ряд
fragm -= fragm.mean()
fragm /= fragm.std()
fragm = fragm.dropna().values # видаляємо зайві нульові значення, якщо є
# розрахунок віконної автокореляції
r_window, _ = nk.signal_autocor(fragm.flatten(), method='correlation')
# розрахунок волатильності по модулям прибутковостей
vol_window = np.mean(np.abs(fragm))
# збереження результатів до масивів
volatility.append(vol_window)
autocorr.append(r_window[1]) 0%| | 0/1393 [00:00<?, ?it/s]100%|██████████| 1393/1393 [00:02<00:00, 557.42it/s]Збережемо результати в окремих текстових файлах:
# збереження результатів ковзної автокореляції
np.savetxt(f"autocorr_name={symbol}_ \
window={window}_step={tstep}_ \
rettype={ret_type}.txt", autocorr)
# збереження результатів ковзної волатильності
np.savetxt(f"volatility_name={symbol}_ \
window={window}_step={tstep}_ \
rettype={ret_type}.txt", volatility)Нарешті, порівняємо динаміку вихідного ряду і розрахованих похідних. Для цього врахуємо, що автокореляцію і волатильність ми знаходили для рухомого вікна. Результати представлено на Рис. 1.6.
fig, ax = plt.subplots(1, 1)
ax2 = ax.twinx()
ax3 = ax.twinx()
ax2.spines.right.set_position(("axes", 1.03))
ax3.spines.right.set_position(("axes", 1.10))
p1, = ax.plot(time_ser.index[window:length:tstep],
time_ser.values[window:length:tstep],
"b-", label=fr"{ylabel}")
p2, = ax2.plot(time_ser.index[window:length:tstep],
autocorr, "g-", label=r"$A$")
p3, = ax3.plot(time_ser.index[window:length:tstep],
volatility, "m-", label=r"$V$")
ax.set_xlabel(xlabel)
ax.set_ylabel(f"{ylabel}")
ax.yaxis.label.set_color(p1.get_color())
ax2.yaxis.label.set_color(p2.get_color())
ax3.yaxis.label.set_color(p3.get_color())
tkw = dict(size=4, width=1.5)
ax.tick_params(axis='y', colors=p1.get_color(), **tkw)
ax2.tick_params(rotation=90, axis='y', colors=p2.get_color(), **tkw)
ax3.tick_params(rotation=30, axis='y', colors=p3.get_color(), **tkw)
ax.tick_params(rotation=45, axis='x', **tkw)
ax3.legend(handles=[p1, p2, p3], fontsize=18)
plt.savefig(f"all_name={symbol}_ret={ret_type}_\
wind={window}_step={tstep}.jpg")
plt.show();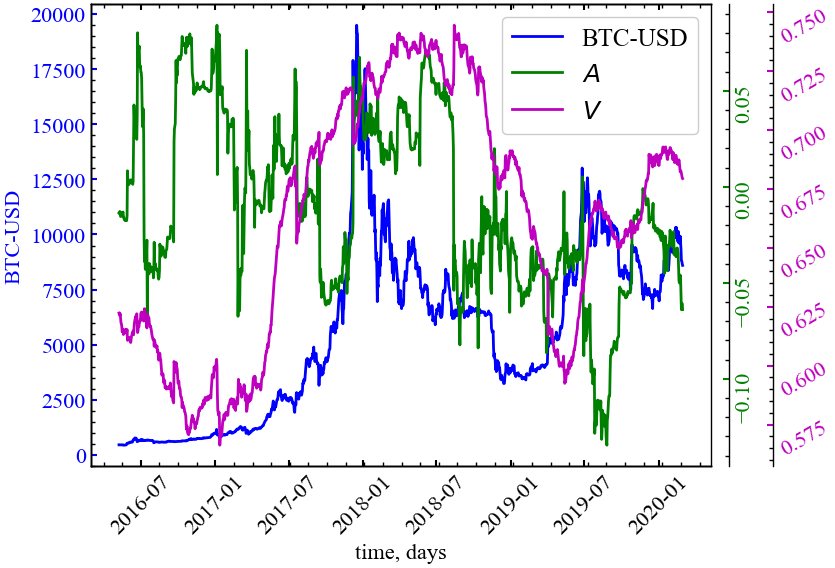
Аналізуючи графік, можна зробити висновок, що у певні моменти спостерігалися стрибки волатильності (як і автокореляції) із поступовим зменшенням її до попереднього рівня, що може бути наслідком збурень у процесі роботи ринку. Аналіз таких збурень, їх частоти та сили, дозволяє виявляти приховані закономірності роботи ринку.
1.3 Висновок
Таким чином, аналіз флуктуацій прибутковостей та волатильностей шляхом побудови функції автокореляції та розподілу ймовірності дозволяє отримати певні висновки, що можуть допомогти в роботі із аналізованими часовими рядами і ринком, з якого взято зазначені часові ряди. Зокрема, у даному випадку, можна надавати корисні рекомендації фінансовим аналітикам.
1.4 Завдання для самостійної роботи
- Отримати індекс часового ряду у викладача
- Провести дослідження згідно інструкції
- Дослідити зміни розрахованих величин для вікон 100 і 500, з кроком 1. Порівняти результати
- Зробити висновки
1.5 Контрольні питання
- Порівняйте вид залежностей флуктуацій цін і прибутковостей. Чому при розрахунках користуються не цінами, а прибутковостями?
- Яку характеристику ряду визначає волатильність?
- У чому причина різних залежностей для прибутковостей та їх модулів?
1.6 Додаток
Для обрання часового індексу часового ряду використаємо дані, що розміщенні на сайті Yahoo! Finance. Оскільки окремі фінансові показники не завжди є доступними, будемо використовувати список компаній, що входять до індексу DJIA. За вказаним посиланням та номером у списку групи оберіть компанію, що входить до індексу та проведіть відповідні розрахунки. Порівняйте отримані результати з такими ж для Біткоїна.